一文看懂现役最强开源模型Qwen3
Qwen3模型家族
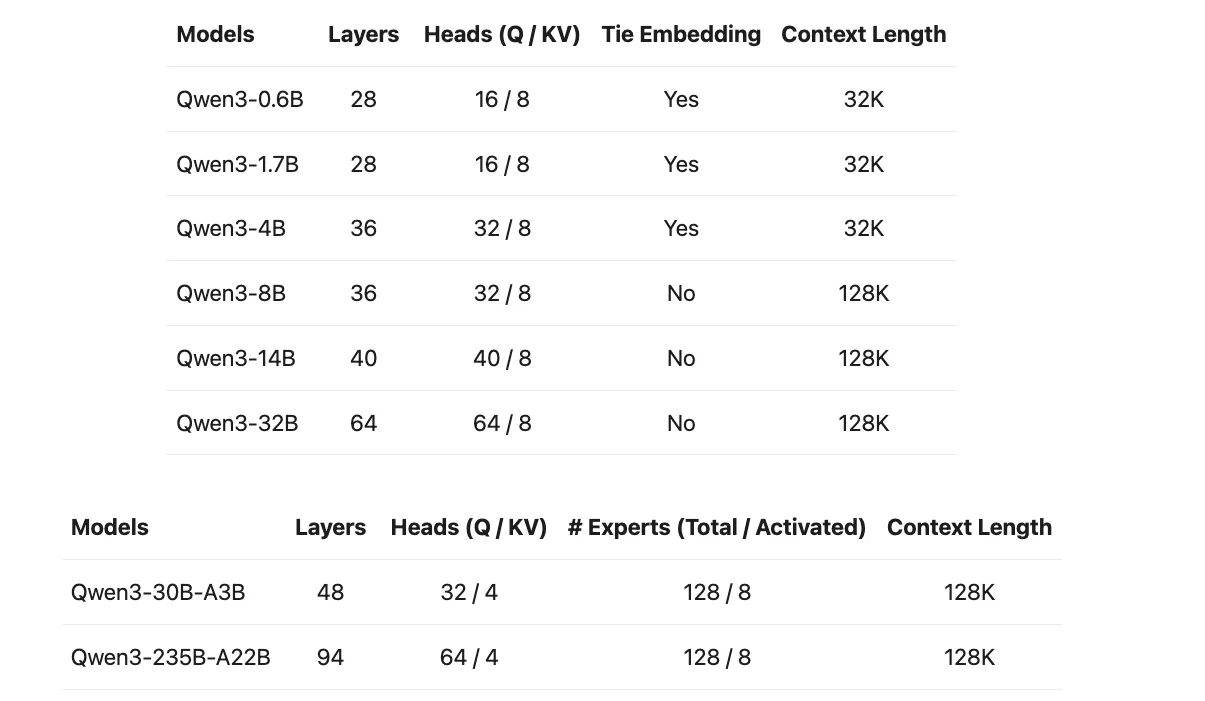
本次千问3开源了两个 MoE 模型:Qwen3-235B-A22B以及Qwen3-30B-A3B, 其中,235B和30B表示模型总参数量,A22B和A3B表示激活的参数量。
此外,六个密集模型也已开源,包括 Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B,以及多种量化的版本。
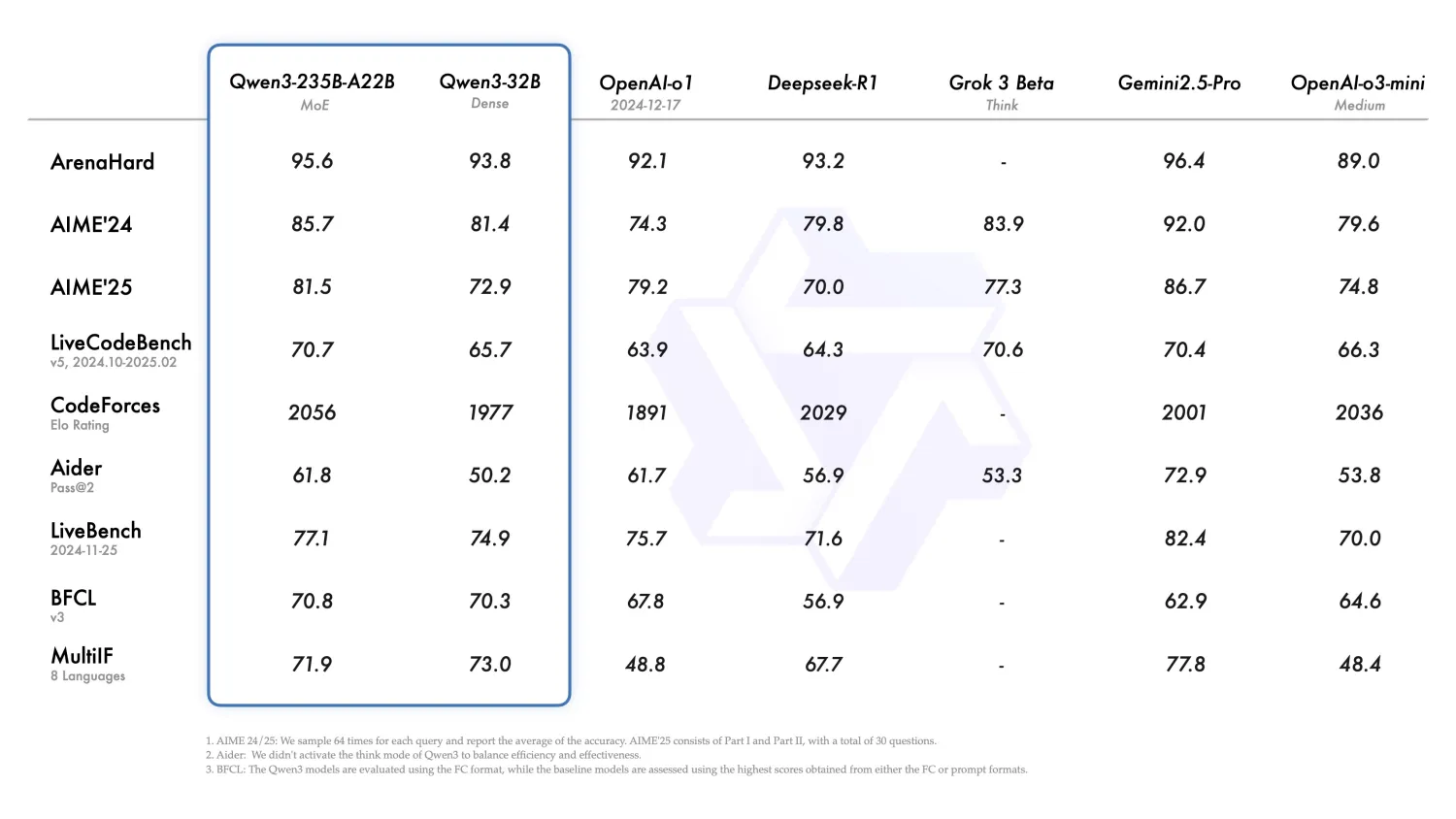
从官方披露的性能测试上,旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,全面超越了DeepSeek-R1,不少地方与Gemini 2.5 Pro十分接近甚至有所超越。
亮点介绍
混合模式
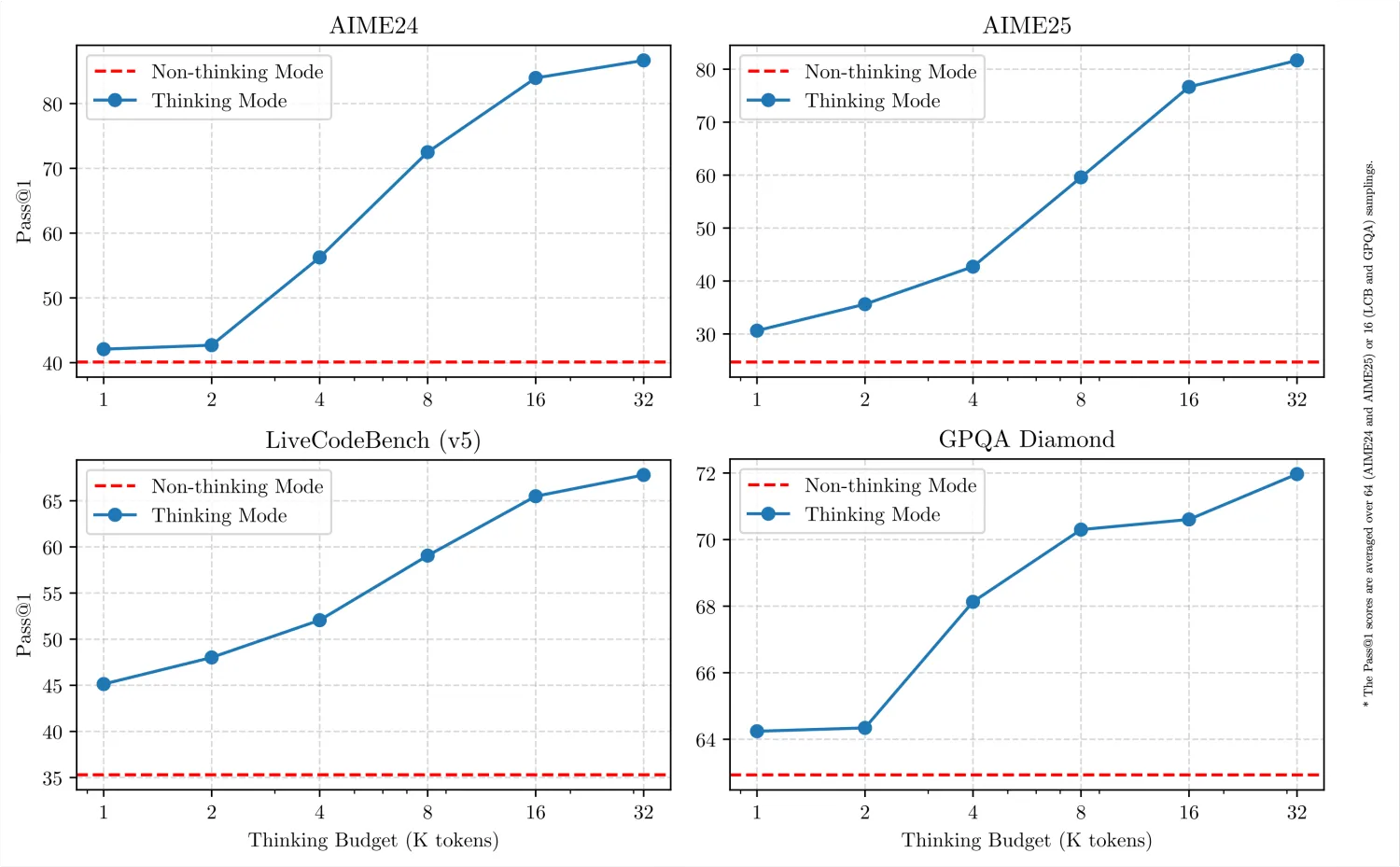
感觉本次Qwen3最大的亮点就是模型原生支持思考模式和非思考模式,可以根据不同的任务需要选择不同的模式,无需跟往常一样同时部署推理模型和对话模型,一个模型即可搞定所有工作。
- 思考模式:在这种模式下,模型会逐步推理,适合需要深入思考的复杂问题。
- 非思考模式:在此模式中,模型提供快速、近乎即时的响应,适用简单问题。
多语种
Qwen3在语言方面卷到极致,支持119 种语言和方言,目标是让全球用户都能直接调用这个模型,无需再经过微调等后处理步骤。

软切换机制
软切换机制是指允许用户在已开启模型推理能力的时候,动态控制模型的行为。操作起来非常简单,只需要在用户提示词或系统消息中添加 /think 和 /no_think ,即可在不同轮次的交互中实现推理或者简单对话。
以下是官方提供的一个代码样例:
# Example Usage if __name__ == "__main__": chatbot = QwenChatbot() # First input (without /think or /no_think tags, thinking mode is enabled by default) user_input_1 = "How many r's in strawberries?" print(f"User: {user_input_1}") response_1 = chatbot.generate_response(user_input_1) print(f"Bot: {response_1}") print("----------------------") # Second input with /no_think user_input_2 = "Then, how many r's in blueberries? /no_think" print(f"User: {user_input_2}") response_2 = chatbot.generate_response(user_input_2) print(f"Bot: {response_2}") print("----------------------") # Third input with /think user_input_3 = "Really? /think" print(f"User: {user_input_3}") response_3 = chatbot.generate_response(user_input_3) print(f"Bot: {response_3}")
训练过程
一、预训练阶段
-
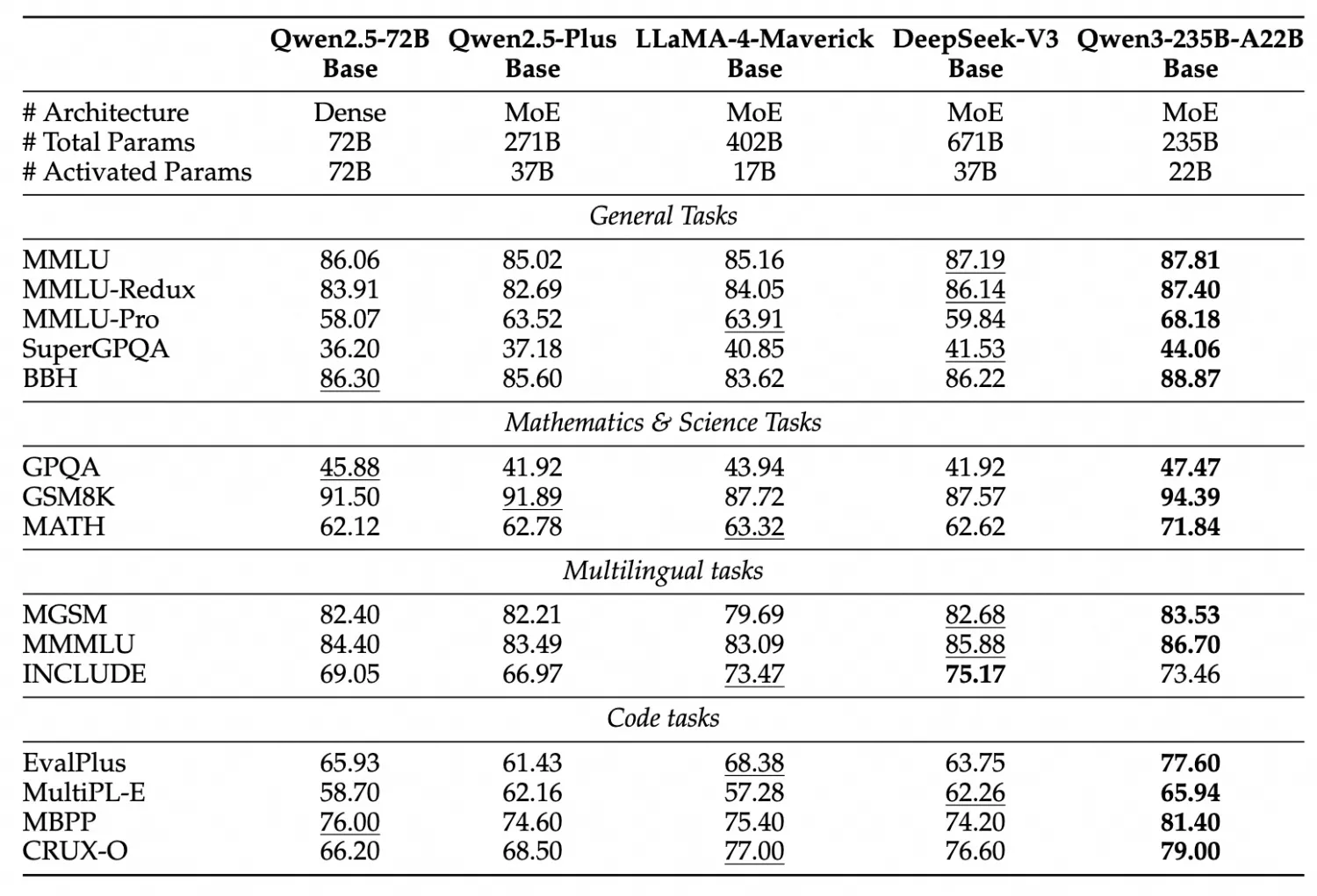
数据规模突破性扩展 Qwen3基于约36万亿token构建训练语料库,较前代Qwen2.5(18万亿token)实现翻倍增长。该数据集涵盖119种语言及方言,通过网页爬取与PDF文档深度挖掘相结合的方式获取。特别采用Qwen2.5-VL提取非结构化文档内容,并利用Qwen2.5-Math和Qwen2.5-Coder两个专用模型生成高质量数学与代码领域数据,显著提升STEM领域知识密度。
-
三阶段渐进式训练机制
● 第一阶段(基础能力建设期):在30万亿token上进行通识教育,建立4K token上下文处理能力,完成基本语言规则与常识性知识的积累。
● 第二阶段(专业技能强化期):针对科技创新需求,将STEM(科学、技术、工程、数学)、编程实践和逻辑推理类数据占比提升至40%,通过5万亿token专项训练强化高阶认知能力。
● 第三阶段(长文本处理突破):构建包含超长学术论文、技术文档的优质语料库,将上下文窗口扩展至32K token,使模型能够完整理解复杂技术方案并进行跨段落关联分析。
二、后训练阶段
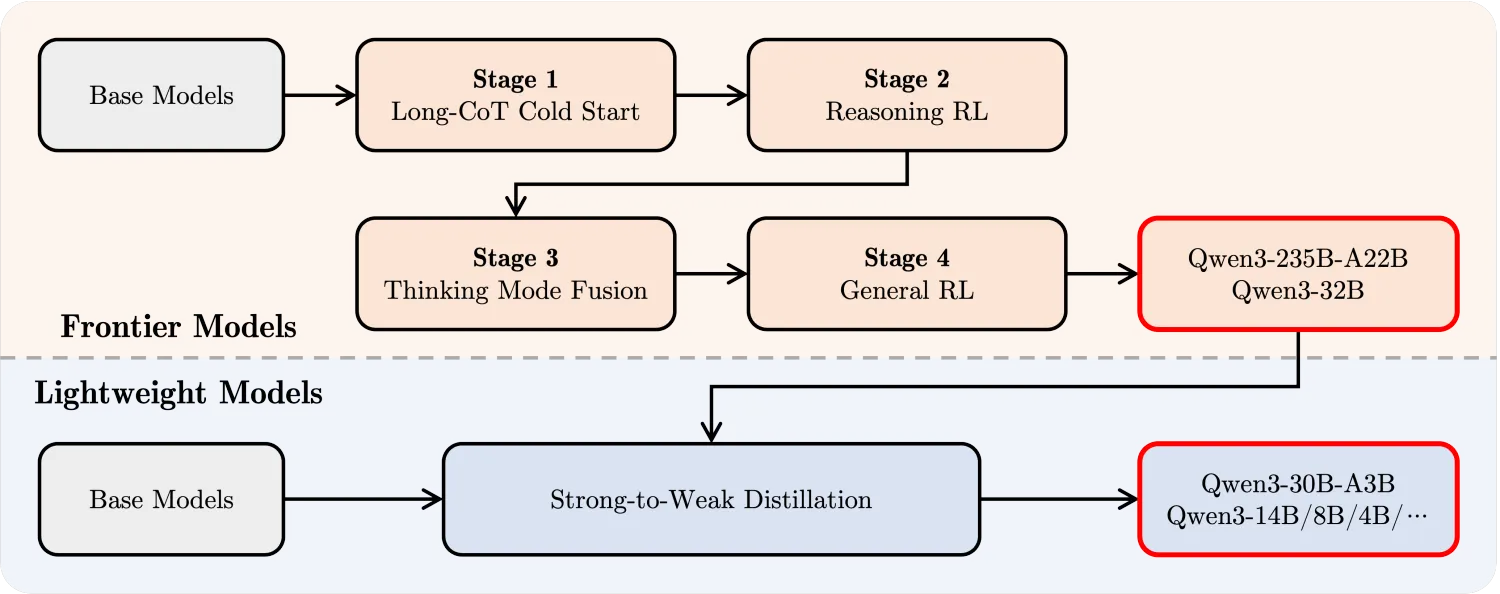
- 四阶段混合训练框架
● 阶段1(深度推理能力奠基):构建覆盖数学证明、程序调试、科学实验设计等领域的长思维链示例库(平均思考路径长度>512 tokens),让模型具备基本的推理能力。
● 阶段2(探索性学习强化):开发基于奖励函数的强化学习环境,鼓励模型在解决复杂数学题、编写多函数程序等任务中尝试非常规解法,提升创造性解决问题的能力。
● 阶段3(双模态认知融合):创新性地将快速响应指令数据(平均响应时间<2s)与深度推理案例进行联合训练,在保证即时交互体验的同时维持复杂问题处理能力,实现两种工作模式的无缝切换。
● 阶段4(通用能力校准): 基于20余类应用场景(含法律咨询、医疗问答、金融分析等)的反馈数据,通过人类偏好排序优化模型输出质量,同步修正潜在行为偏差。
这个流程图看着与DeepSeek R1技术文档非常相似,前面2个阶段基本一致,Qwen3增加了推理/非推理模式融合策略。同时也通过对强大的模型进行蒸馏,提取具备推理能力的小模型。
使用方法
transformer
可以直接使用transformer库,基本不需要改动什么代码即可调用Qwen3系列模型。
from modelscope import AutoModelForCausalLM, AutoTokenizer model_name = "Qwen/Qwen3-30B-A3B" # load the tokenizer and the model tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto" ) # prepare the model input prompt = "Give me a short introduction to large language model." messages = [ {"role": "user", "content": prompt} ] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, enable_thinking=True # Switch between thinking and non-thinking modes. Default is True. ) model_inputs = tokenizer([text], return_tensors="pt").to(model.device) # conduct text completion generated_ids = model.generate( **model_inputs, max_new_tokens=32768 ) output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() # parsing thinking content try: # rindex finding 151668 (</think>) index = len(output_ids) - output_ids[::-1].index(151668) except ValueError: index = 0 thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n") content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n") print("thinking content:", thinking_content) print("content:", content)
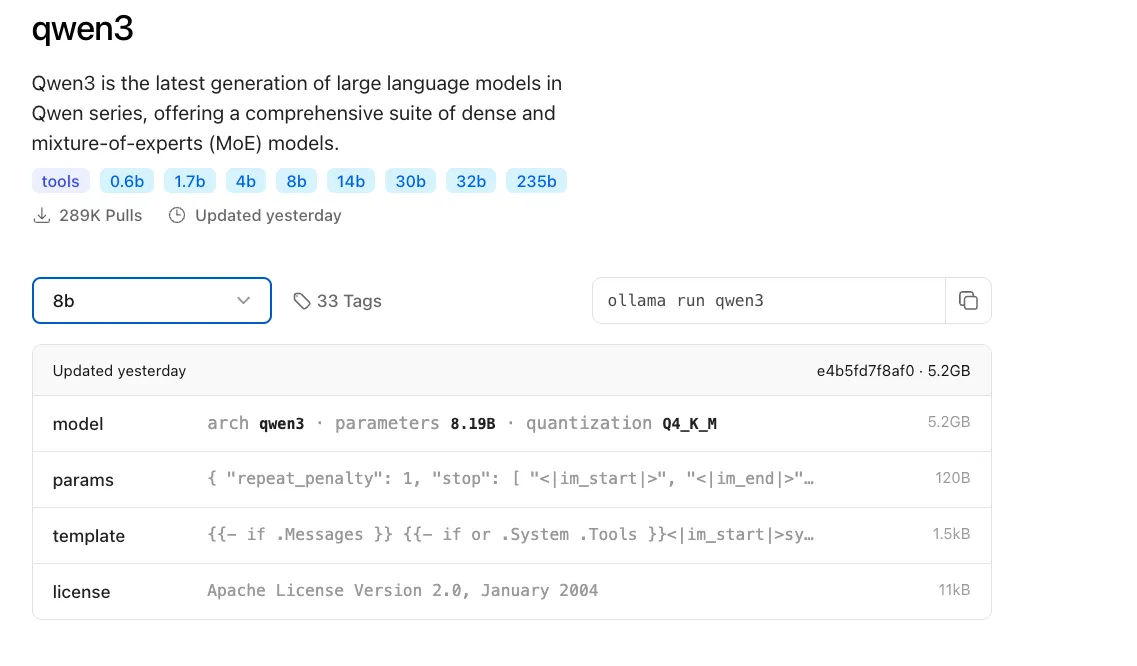
ollama
ollama已经上架了包含量化版本在内的共33个模型,从0.6B~235B不等,可以根据自己硬件设备选择恰当的模型。
链接:https://ollama.com/library/qwen3
服务部署
Qwen3同样支持流行的部署框架,可以使用 sglang>=0.4.6.post1 或 vllm>=0.8.4 来创建一个与OpenAI API 兼容的Rest API:
vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser qwen3
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B --reasoning-parser qwen3
展望
千问团队接下来还会从几个方面进行提升:扩展数据规模、增加模型大小、延长上下文长度、拓宽模态范围,这些都是实打实的实现AGI的必经之路。从本地Qwen3的训练过程也可以看到,目前大模型的预训练数据量已经很难有非常大的提升了,只能通过更好的模型去合成相应的数据,这对于大厂来说有先天优势,以后在大模型领域的马太效应会越来越明显。
推荐阅读
LLM本质上是无状态的模型,每次调用都像一次“短暂失忆”。为了让 AI Agent真正理解上下文、具备个性化交互和任务持续性,引入记忆系统至关重要。
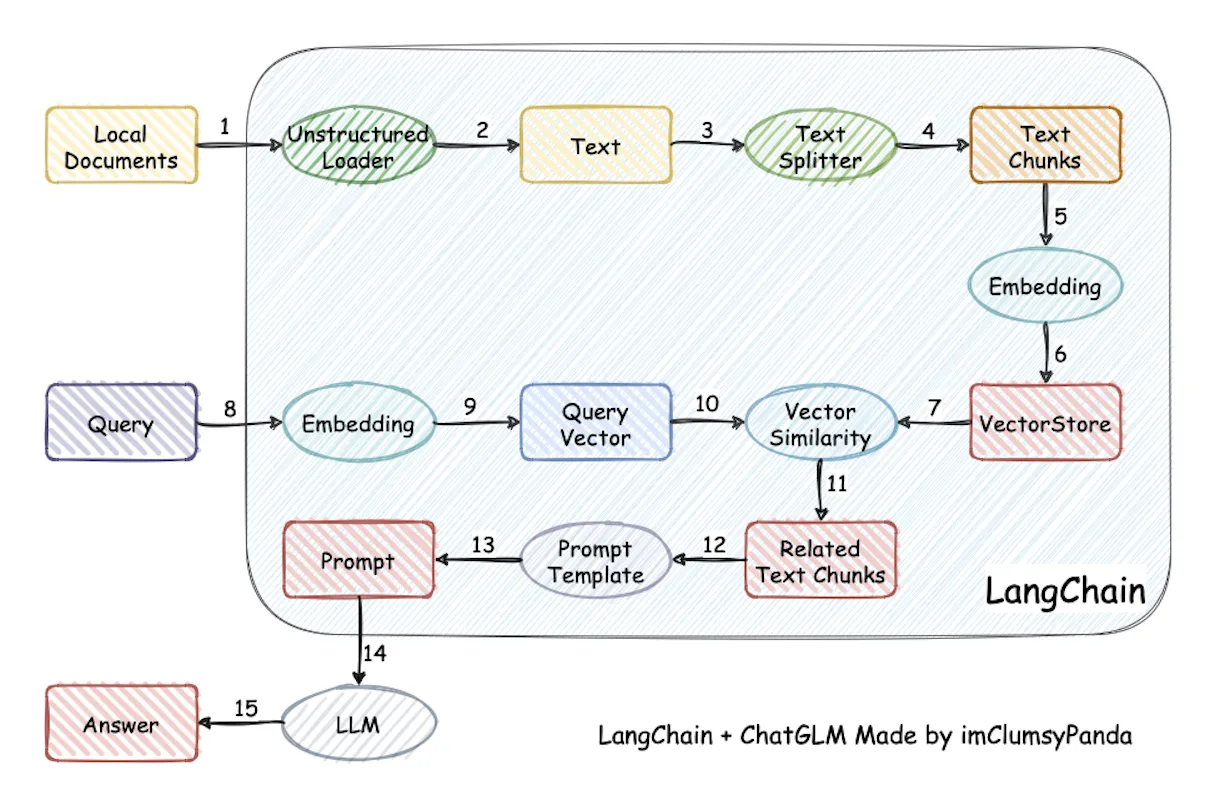
在传统RAG流程中,必不可少的一个步骤是把长文档进行分块,然后把这些文本块进行向量化处理,并且存放在向量数据库中,当查询的时候,则从数据库中检索出相似的文本块传递给大模型,用于生成响应。
