OpenClaw会话管理深度解析
在OpenClaw的架构中,会话管理是连接 AI Agent与多渠道消息系统的核心枢纽。与传统的 CLI 工具不同,OpenClaw 运行的是一个持久化的守护进程,这个进程需要在一段时间内维护与多个用户、多个渠道的对话状态。本文将深入探讨 OpenClaw 的会话管理机制,从存储结构到生命周期管理,再到上下文压缩与修剪,尽量呈现完整的技术细节。
一、会话管理的核心概念
OpenClaw 将每个会话视为一个独立的对话单元,它不仅要跟踪用户发送的消息和 AI 的回复,还要管理工具调用的结果、Token 消耗统计、以及各种渠道特定的上下文信息。一个设计良好的会话管理系统需要解决几个关键问题:如何在多个渠道间隔离对话、如何在有限的上下文窗口内塞入更多有价值的内容、以及如何在会话生命周期结束时妥善清理资源。
在OpenClaw中,Gateway是所有会话状态的唯一权威来源。无论什么客户端,都必须向Gateway查询会话列表和Token统计信息,而不能直接读取本地文件。这种设计确保了分布式部署场景下的一致性,当你运行多个OpenClaw节点时,会话状态不会因为客户端直接操作而产生冲突。
OpenClaw采用一种分层的方式来组织会话。一个Agent可以同时与多个渠道的多个用户进行对话,这些对话被组织成树状结构:根节点是Agent身份,下一级是会话类型(比如私信、群组、线程等),再往下是具体的会话标识符。这种设计既保证了会话之间的隔离,又方便进行批量管理操作。
二、会话存储架构
2.1 文件系统布局
OpenClaw的会话数据存储在用户的主目录下,具体路径遵循一个清晰的结构。Agent的工作空间、内存索引和配置文件都按照Agent身份进行隔离,确保多Agent部署时不会发生上下文污染。标准的目录结构如下所示,每个Agent都有自己独立的目录,里面包含工作区文件、向量数据库内存、会话转录和元数据存储。
~/.openclaw/ ├── config.json # 全局配置 └── agents/ ├── main/ # 默认Agent │ ├── workspace/ # Agent工作区文件 │ ├── memory/ # SQLite 向量数据库 │ │ └── memory.db │ ├── sessions/ # 会话转录文件 │ │ ├── main.jsonl # 主会话转录 │ │ ├── [email protected] # 电报会话 │ │ └── group:slack:C123456.jsonl │ └── store.json # 会话元数据存储 └── assistant/ # 次级Agent └── ...
2.2 会话转录文件格式
会话转录采用JSONL格式存储,每一行是一个独立的JSON对象,代表对话中的一个事件。这种格式的优势在于支持高效的追加写入——每次新增消息时不需要读取整个文件,只需要追加一行即可。同时,JSONL的树状结构通过 id 和 parentId 字段来维护,使得对话历史可以构建出完整的树形结构。
转录文件由 @mariozechner/pi-coding-agent 的SessionManager负责管理。
// 会话转录文件条目示例 {"id": "msg_001", "parentId": null, "type": "user", "content": "帮我写一个排序算法"} {"id": "msg_002", "parentId": "msg_001", "type": "assistant", "content": "好的,我来实现..."} {"id": "msg_003", "parentId": "msg_002", "type": "tool_use", "tool": "write", "name": "sort.ts"} {"id": "msg_004", "parentId": "msg_003", "type": "tool_result", "content": "文件已创建"} {"id": "msg_005", "parentId": "msg_004", "type": "assistant", "content": "我已经创建了排序算法文件..."}
2.3 元数据存储
除了转录文件,每个Agent还有一个 store.json 文件,用于存储会话的元数据信息。这个文件包含了会话的各种统计信息,如输入Token数、输出Token数、总Token数和上下文Token数。
// store.json 结构示例 { "sessions": { "main:whatsapp:+1234567890": { "id": "sess_abc123", "mainKey": "main", "agentId": "main", "channel": "whatsapp", "peer": "+1234567890", "createdAt": "2026-03-10T08:30:00Z", "updatedAt": "2026-03-13T15:20:00Z", "inputTokens": 45000, "outputTokens": 12000, "totalTokens": 57000, "contextTokens": 80000, "model": "claude-sonnet-4-20250514", "origin": { "label": "WhatsApp Direct", "routing": ["whatsapp", "+1234567890"] } } } }
2.4 缓存机制
会话存储的读取操作经过缓存优化,默认TTL为 45 秒,以减少磁盘 I/O。这种缓存策略在高频访问场景下效果显著,同时缓存失效机制会在数据更新时自动触发。如果需要绕过缓存进行测试,可以使用专用的缓存旁路接口。
// 会话存储缓存实现伪代码 class SessionStore { private cache: Map<string, {="" data:="" sessiondata;="" timestamp:="" number="" }=""> = new Map(); private readonly CACHE_TTL = 45 * 1000; // 45秒 async getSession(sessionKey: string): Promise<sessiondata |="" null=""> { const cached = this.cache.get(sessionKey); if (cached && Date.now() - cached.timestamp < this.CACHE_TTL) { return cached.data; } // 从磁盘读取 const data = await this.readFromDisk(sessionKey); this.cache.set(sessionKey, { data, timestamp: Date.now() }); return data; } async updateSession(sessionKey: string, updates: Partial<sessiondata>): Promise<void> { // 写入磁盘 await this.writeToDisk(sessionKey, updates); // 使缓存失效 this.cache.delete(sessionKey); } } </void></sessiondata></sessiondata></string,>
三、会话生命周期管理
3.1 会话创建与会话键
当用户首次通过某个渠道向Agent发送消息时,OpenClaw会根据消息的来源创建一个新的会话。会话键(sessionKey)是这个过程中的核心概念,它决定了会话的路由和隔离策略。会话键的格式遵循 agent: agentId: scope: channel: peer 的模式,不同的渠道和会话类型会产生不同的键值。
OpenClaw为不同类型的对话提供了灵活的键映射策略。直接聊天会被映射到 agent: agentId: main(默认情况),这意味着同一个Agent与同一个用户的多个直接对话会共享同一个会话上下文。而群组聊天和频道聊天则各自拥有独立的会话键,确保不同conversation的历史不会被混淆。
// 会话键映射规则伪代码 function resolveSessionKey( agentId: string, channel: string, peer: string, scope: 'per-sender' | 'per-account-channel-peer' | 'main', messageType: 'dm' | 'group' | 'thread' ): string { if (messageType === 'dm' && scope === 'main') { return `agent:${agentId}:main`; } if (messageType === 'group') { return `agent:${agentId}:group:${channel}:${peer}`; } if (messageType === 'thread') { return `agent:${agentId}:thread:${channel}:${peer}`; } // 默认:每个发送者一个会话 return `agent:${agentId}:dm:${channel}:${peer}`; }
3.2 重置策略
会话重置是会话生命周期管理中的重要环节。OpenClaw提供了多种重置策略,以适应不同的使用场景。
每日重置是最常用的策略。默认情况下,会话会在每天凌晨 4 点进行重置。一旦会话的最后更新时间早于最近的每日重置时间,该会话就会被视为过期。下次收到消息时,OpenClaw 会创建一个全新的会话。
// 每日重置配置示例 { "session": { "reset": { "mode": "daily", "atHour": 4 } } }
空闲重置是另一种可选策略。当你配置了 idleMinutes 参数后,系统会跟踪会话的空闲时间。如果用户在指定的时间内没有任何活动,会话就会自动重置。当同时配置了每日重置和空闲重置时,两个条件中任何一个先满足,就会触发会话重置。
// 空闲重置配置示例 { "session": { "reset": { "mode": "daily", "atHour": 4, "idleMinutes": 120 } } }
按类型重置允许你为不同类型的会话设置不同的策略。例如,直接聊天方式可能需要更长的上下文保持时间(240 分钟空闲),而群组会话可能需要更频繁地重置(120 分钟空闲)。
// 按类型重置配置示例 { "session": { "resetByType": { "dm": { "mode": "idle", "idleMinutes": 240 }, "group": { "mode": "idle", "idleMinutes": 120 }, "thread": { "mode": "daily", "atHour": 4 } } } }
手动触发重置通过特殊的消息指令来实现。用户可以发送 /new 或 /reset来立即重置会话。如果发送的是 /new <model>,OpenClaw还会切换到指定的模型。当 /new 或 /reset 单独发送时,OpenClaw会运行一个简短的“你好”问候轮次来确认会话已重置。
// 重置触发器处理伪代码 async function handleResetTrigger(message: string, session: Session): Promise<session> { if (!isResetTrigger(message)) { return session; } const parts = message.split(' '); const command = parts[0]; const arg = parts.slice(1).join(' '); // 创建新会话 const newSession = createNewSession(session.agentId, session.channel, session.peer); if (command === '/new' && arg) { // 解析并设置模型 newSession.model = resolveModel(arg); } if (command === '/reset' || (command === '/new' && !arg)) { // 运行问候轮次 await runGreetingTurn(newSession); } return newSession; } </session>
3.3 孤立cron作业
对于定时任务,OpenClaw采用了不同的策略。每次cron作业运行时,它都会创建一个全新的会话标识符,而不是复用之前的会话。这种设计确保了定时任务的独立性和可预测性,避免了历史对话对定时任务执行的意外影响。
四、会话修剪机制
会话修剪(Session Pruning)是OpenClaw管理上下文的重要手段。它与压缩(Compaction)不同。修剪是临时性的,只影响单次 LLM 调用时的内存中的上下文,不会持久化到磁盘的 JSONL 文件。
4.1 修剪的触发条件
修剪机制只在特定条件下触发。当启用 mode: "cache-ttl" 并且距离上一次 Anthropic API 调用已经超过配置的 TTL 时间时,修剪才会运行。这种设计是为了配合Anthropic的提示缓存机制,提示缓存只在 TTL 时间内有效,超过 TTL 后下一次请求需要重新缓存整个提示,除非先进行修剪。这样做使用Anthropic模型时可以有效节省token。
// 启用 TTL 感知修剪配置 { "agent": { "contextPruning": { "mode": "cache-ttl", "ttl": "5m" } } }
4.2 软修剪与硬修剪
OpenClaw实现了两种修剪策略:软修剪和硬修剪。
软修剪专门针对过大的工具结果。它会保留结果的头部和尾部,中间用省略号替换,并附上原始大小的说明。这种方式让 AI 仍然能够了解到工具执行过,只是细节被压缩了。包含图像块的工具结果会被跳过,不会被修剪。
// 软修剪伪代码 function softTrim(toolResult: ToolResult, options: SoftTrimOptions): ToolResult { const { maxChars, headChars, tailChars } = options; if (toolResult.content.length <= maxChars) { return toolResult; } // 保留头部和尾部 const head = toolResult.content.substring(0, headChars); const tail = toolResult.content.substring(toolResult.content.length - tailChars); const originalSize = toolResult.content.length; return { ...toolResult, content: `${head} [...省略了 ${originalSize - headChars - tailChars} 字符...] ${tail} [原始工具结果大小: ${originalSize} 字符]` }; }
硬修剪则更加激进,它会用占位符完全替换工具结果的内容。当工具结果特别长或者完全不需要保留时,这种方式可以最大程度地节省上下文空间。
// 硬修剪伪代码 function hardClear(toolResult: ToolResult, placeholder: string): ToolResult { return { ...toolResult, content: placeholder, _isHardCleared: true }; }
4.3 保护机制
为了避免重要信息被意外修剪,OpenClaw设置了保护规则。最后 keepLastAssistants 个助手消息会被保护,其后的工具结果才会被考虑修剪。如果会话中没有足够的助手消息来建立这个截止点,修剪会被跳过。工具结果中的图像块也永远不会被修剪,因为这些信息对于理解对话上下文至关重要。
// 修剪决策伪代码 function shouldPruneToolResult( toolResult: ToolResult, assistantMessages: Message[], keepLastAssistants: number ): boolean { // 包含图像块的工具结果不修剪 if (hasImageBlocks(toolResult)) { return false; } // 没有足够的助手消息来建立截止点 if (assistantMessages.length < keepLastAssistants) { return false; } // 检查工具结果是否在保护范围内 const cutoffIndex = assistantMessages.length - keepLastAssistants; return toolResult.turnIndex > cutoffIndex; }
4.4 上下文窗口估算
修剪操作需要知道模型的上下文窗口大小。OpenClaw 按照以下顺序来确定上下文窗口:首先检查 models.providers.*.models[].contextWindow 配置覆盖,然后使用模型注册表中的定义,最后使用默认的20w Token。如果设置了 agents.defaults.contextTokens,它会被视为上限,即最小值。
五、上下文压缩
5.1 压缩的工作原理
压缩在Agent系统中都比较常见,它会将旧的对话历史总结为一个紧凑的摘要,并保留压缩点之后的最近消息。这个摘要会被存储在会话的 JSONL 历史中,所以未来的请求会使用:压缩摘要 + 压缩点之后的最近消息。这种方式实现了上下文空间的重复利用,同时保留了对话的关键信息。
// 压缩流程伪代码 async function compactSession(session: Session): Promise<compactionresult> { // 1. 确定压缩点:保留最近的 N 条消息 const recentMessages = session.messages.slice(-SESSION_KEEP_COUNT); // 2. 将要压缩的消息发送给 LLM 进行总结 const messagesToSummarize = session.messages.slice(0, -SESSION_KEEP_COUNT); const summary = await summarizeMessages(messagesToSummarize); // 3. 创建压缩摘要消息 const compactionMessage: Message = { id: generateId(), type: 'compaction_summary', content: summary, originalMessageCount: messagesToSummarize.length, timestamp: Date.now() }; // 4. 更新会话:保留压缩消息 + 最近消息 session.messages = [compactionMessage, ...recentMessages]; // 5. 持久化到 JSONL await saveSessionToDisk(session); return { success: true, compactedCount: messagesToSummarize.length, newSummaryLength: summary.length }; } </compactionresult>
5.2 自动压缩
自动压缩默认是开启的。当会话接近或超过模型的上下文窗口时,OpenClaw 会触发自动压缩,并可能使用压缩后的上下文重试原始请求。在详细模式下,你会看到 Auto-compaction complete 的提示。/status 命令也会显示压缩次数。
自动压缩在两种情况下会被触发。第一种是溢出恢复:模型返回上下文溢出错误时,OpenClaw 会执行压缩然后重试。第二种是阈值维护:在成功的轮次之后,如果上下文 Token 数超过了配置的阈值,就会触发压缩。
// 自动压缩触发伪代码 async function handleLLMResponse(response: LLMResponse, session: Session): Promise<void> { if (response.error?.code === 'context_overflow') { // 情况1:溢出恢复 console.log('🧹 Context overflow detected, triggering compaction...'); await compactSession(session); console.log('🧹 Auto-compaction complete, retrying request...'); // 使用压缩后的上下文重试 return await retryWithCompactedContext(session, response.originalPrompt); } // 情况2:阈值维护 const contextTokens = await estimateContextTokens(session); const threshold = getModelContextThreshold(session.model); if (contextTokens > threshold) { console.log(`🧹 Context tokens (${contextTokens}) exceed threshold (${threshold}), triggering compaction...`); await compactSession(session); } } </void>
5.3 手动压缩
用户可以通过 /compact 命令手动触发压缩。这个命令可以带参数也可以不带参数。如果不带参数,OpenClaw 会使用默认策略进行压缩。如果带参数,参数内容会被用作压缩的指导提示,告诉 LLM 在总结历史时应该关注哪些方面。
/compact /compact 重点关注代码修改和决策
5.4 压缩前的内存刷新
在自动压缩发生之前,OpenClaw 可以执行一个静默的内存刷新轮次。这会提示模型将重要的信息写入工作区的持久化笔记文件中。这个特性只有在工作区可写时才会启用,是连接会话上下文和持久化记忆的重要桥梁。
// 内存刷新伪代码 async function flushMemoryBeforeCompaction(session: Session): Promise<void> { if (!session.workspace.writable) { return; // 工作区不可写,跳过 } // 构建内存刷新提示 const flushPrompt = buildMemoryFlushPrompt(session); // 静默执行,不发送给用户 const result = await runSilentTurn(session, flushPrompt); // 模型应该已经将重要信息写入工作区的笔记文件 await addNoteToWorkspace(session.workspace, result.durableNotes); } </void>
5.5 压缩与修剪的对比
理解压缩和修剪的区别对于正确配置 OpenClaw 非常重要。压缩是持久化的,它会修改 JSONL 文件,将历史消息替换为总结。而修剪是临时性的,它只影响单次请求中发送给模型的上下文,不会修改磁盘上的历史记录。压缩总结了完整的对话历史(包括用户消息、助手消息和工具结果),而修剪只处理工具结果。
| 特性 | 压缩 (Compaction) | 修剪 (Pruning) |
|---|---|---|
| 持久化 | 写入 JSONL 文件 | 不修改磁盘文件 |
| 作用范围 | 整个对话历史 | 仅工具结果 |
| 触发方式 | 自动或手动 | 基于 TTL 的条件触发 |
| 数据保留 | 压缩为摘要 | 软修剪保留头尾,硬修剪完全替换 |
六、高级特性
6.1 发送策略
OpenClaw支持配置发送策略,允许你根据会话类型阻止消息传递,而不需要逐个列出会话 ID。这是一个方便的管理功能,特别适合在测试或维护期间控制特定类型会话的消息流动。
// 发送策略配置示例 { "session": { "sendPolicy": { "block": { "types": ["group", "thread"], "reason": "Maintenance in progress" } } } }
运行时覆盖(仅所有者可用)允许临时修改发送策略,而不需要修改配置文件。
6.2 身份链接
身份链接功能允许将同一个用户在不同渠道的身份关联起来。例如,你可以将用户的Telegram账号和Discord 账号链接在一起,这样无论用户从哪个渠道发送消息,都会进入同一个会话。
// 身份链接配置示例 { "session": { "identityLinks": { "alice": ["telegram:123456789", "discord:987654321012345678"], "bob": ["telegram:111111111", "slack:U12345678"] } } }
6.3 并发控制
会话存储的并发访问通过每路径锁队列系统来管理。这种设计确保了即使在高并发场景下,也不会出现数据竞争和不一致的问题。锁是按存储路径隔离的,不同的会话不会相互阻塞。
// 并发控制伪代码 class SessionStore { private locks: Map<string, asyncqueue=""> = new Map(); async withLock<t>( sessionKey: string, operation: () => Promise<t> ): Promise<t> { // 获取或创建该会话路径的锁队列 const lock = this.getOrCreateLock(sessionKey); // 获取锁 await lock.acquire(); try { // 执行操作 return await operation(); } finally { // 释放锁 lock.release(); } } private getOrCreateLock(sessionKey: string): AsyncQueue { if (!this.locks.has(sessionKey)) { this.locks.set(sessionKey, new AsyncQueue()); } return this.locks.get(sessionKey)!; } } </t></t></t></string,>
6.4 边界安全文件读取
为了防止内存问题,转录操作使用边界安全的文件读取方式。这种方式确保即使遇到特大的转录文件,也不会一次性将整个文件加载到内存中,而是采用流式或分块的方式进行处理。
七、配置示例
下面是一个完整的会话管理配置示例,展示了各种选项的组合使用:
{ "session": { "scope": "per-sender", "dmScope": "main", "identityLinks": { "alice": ["telegram:123456789", "discord:987654321012345678"] }, "reset": { "mode": "daily", "atHour": 4, "idleMinutes": 120 }, "resetByType": { "thread": { "mode": "daily", "atHour": 4 }, "dm": { "mode": "idle", "idleMinutes": 240 }, "group": { "mode": "idle", "idleMinutes": 120 } }, "resetByChannel": { "discord": { "mode": "idle", "idleMinutes": 10080 } }, "resetTriggers": ["/new", "/reset", "/restart"], "store": "~/.openclaw/agents/{agentId}/sessions/sessions.json", "mainKey": "main" }, "agent": { "contextPruning": { "mode": "cache-ttl", "ttl": "5m", "keepLastAssistants": 3, "softTrim": { "maxChars": 4000, "headChars": 1500, "tailChars": 1500 }, "hardClear": { "enabled": true, "placeholder": "[旧工具结果内容已清除]" } }, "defaults": { "compaction": { "enabled": true, "keepRecentMessages": 50 } } } }
八、总结
OpenClaw的会话管理是一个复杂而精密的系统,它处理了从会话创建、状态维护到资源清理的完整生命周期。通过 JSONL 转录文件与元数据存储的结合,OpenClaw 实现了高效的历史查询和持久化。会话键映射机制提供了灵活的路由和隔离策略,而重置策略则确保了长时间运行的会话不会无限累积上下文。
修剪和压缩机制是会话管理的核心优化手段。修剪通过临时清理工具结果来配合提示缓存的 TTL 行为,而压缩则通过持久化总结来延长会话的可运行时间。两者配合使用,可以在保持对话连贯性的同时,最大化利用有限的上下文窗口。
理解这些机制对于优化 OpenClaw 的使用体验非常重要。合理配置重置策略可以避免会话变得过于笨重,启用修剪可以配合提示缓存节省成本,而适时手动压缩则可以在关键时候恢复会话的响应能力。
推荐阅读
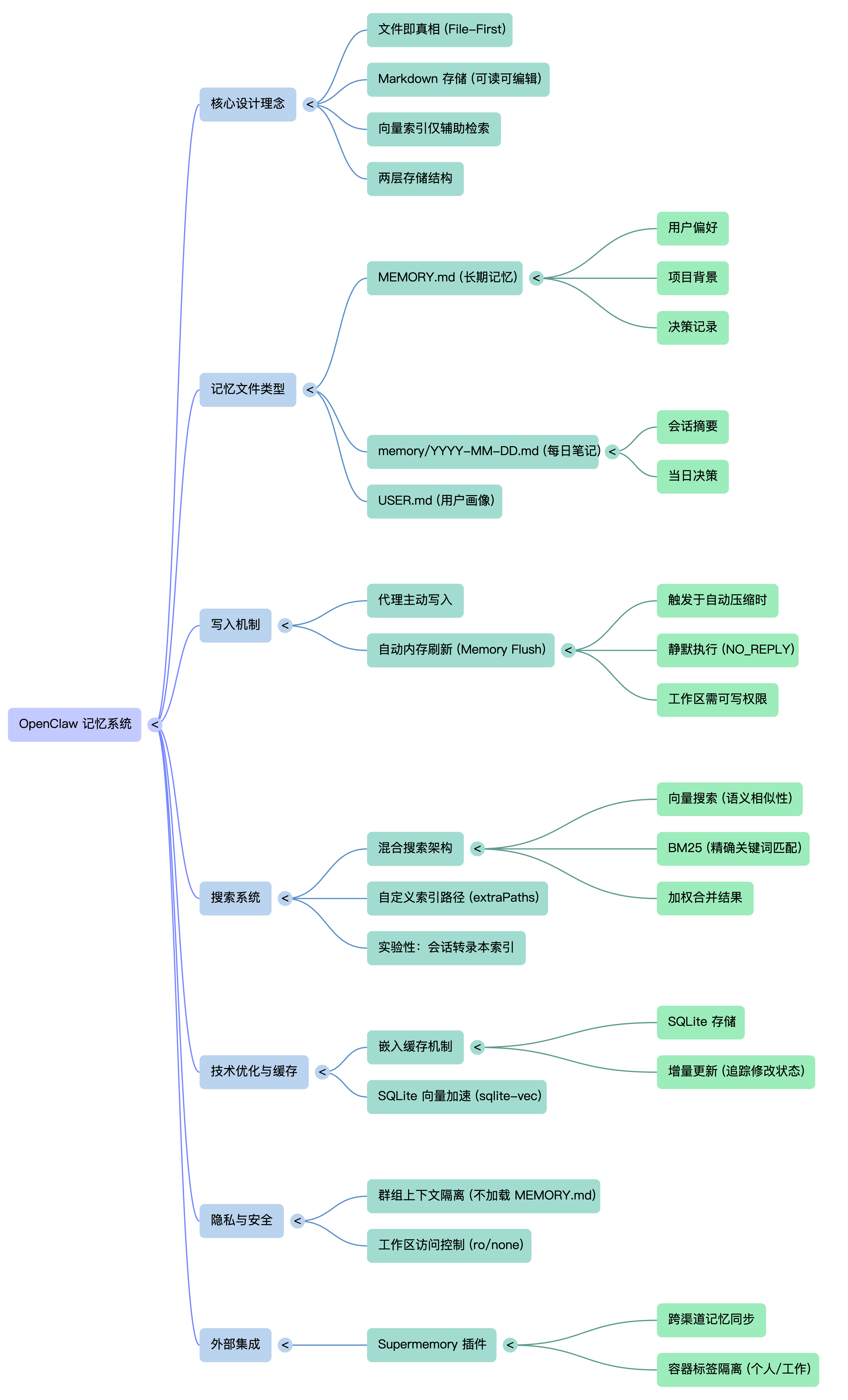
OpenClaw选了一条中间路线,与Skills类似,记忆是普通的Markdown文件,而且也是放在本地的磁盘上进行存储的。
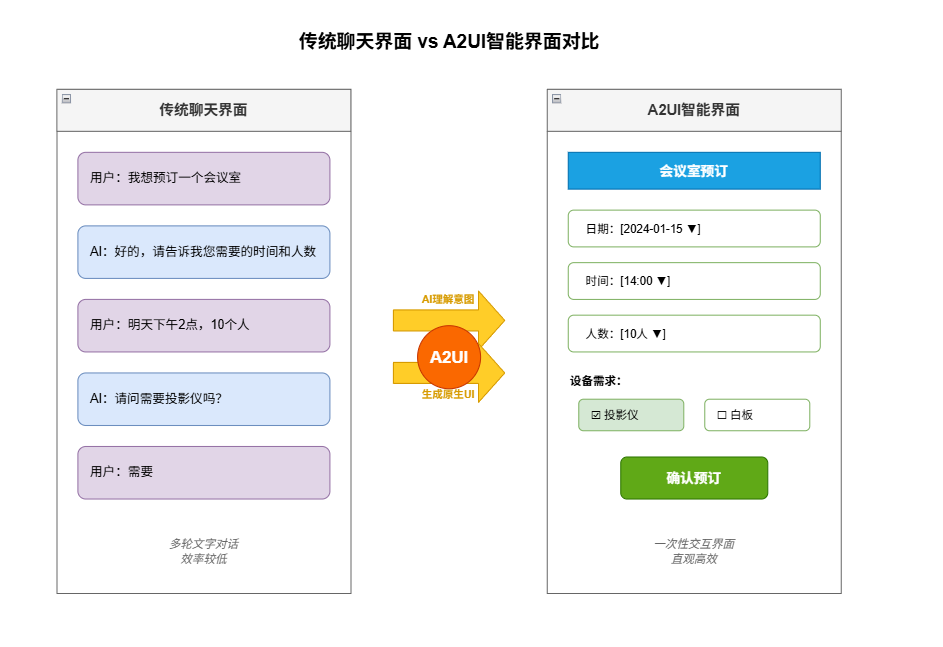
在笔者看来,A2UI的意义不只是多了一种UI方案,而是在于它补齐了Agent从思考到执行的最后一环。对于Agent的开发者来说,可能不再需要去写各种业务相关的界面,而是可以专注于设计Agent能力边界。而Agent的终极形态,不再是聊天机器人,而是会自己搭界面的智能系统。 A2UI,可能正是这个方向上非常关键的一步。
