OpenClaw多智能体协作与工具实现深度解析
一、Sub-Agent的注册与调用
1.1 Sub-Agent的本质
Sub-Agent不是独立的Agent,而是主Agent派生出来的后台任务。它运行在自己的会话里,会话key长这样:agent:<agentId>: subagent:<uuid>。注意这个 key 结构,它明确标识了这是一个子代理,而不是顶级 Agent。
Sub-Agent最大的价值是隔离。主Agent的上下文不会被子任务污染,子Agent跑完以后把结果汇报回来,主Agent再决定下一步。
// 调用 sessions_spawn 启动子代理 { tool: 'sessions_spawn', input: { task: "帮我查一下 Rust 和 Go 在并发性能上的对比", label: "rust-vs-go-research", // 方便后续追踪 agentId: "worker", // 指定用哪个 Agent 配置 model: "anthropic/claude-sonnet-4-5", // 可以单独指定模型 runTimeoutSeconds: 300, thread: true // 是否绑定到频道线程 } }
1.2 权限控制
Agent之间如何知道谁能调用谁?默认情况下,Agent间通信是关闭的,必须手动启用。
{ "tools": { "agentToAgent": { "enabled": true, "allow": ["main", "worker", "researcher"] } } }
allow 数组定义了哪些Agent ID可以被 sessions_spawn 调用。如果这里没配对,即使代码写了也白搭,你会看到agentId is not allowed for sessions_spawn错误。
1.3 子Agent能用什么工具
默认情况下,子Agent能用除了会话工具之外的所有工具。这是有意的设计,因为子Agent只是被当成一个后台任务来运行,不应该能操控其他会话。
但如果你启用了嵌套子Agent(maxSpawnDepth >= 2),depth-1的子Agent会额外获得 sessions_spawn、subagents、sessions_list、sessions_history,只有这样它才能管理自己的子任务。
{ "agents": { "defaults": { "subagents": { "maxSpawnDepth": 2, // 允许两层嵌套 "maxChildrenPerAgent": 5 // 每个 Agent 最多同时跑 5 个子任务 } } } }
不同深度级别的Agent工具差异如下:
| 深度 | 会话 key 模式 | 角色 | 能否spawn |
|---|---|---|---|
| 0 | agent:<id>: main | 主 Agent | 永远可以 |
| 1 | agent:<id>: subagent:<uuid> | 子 Agent | 仅当 maxSpawnDepth >= 2 |
| 2 | agent:<id>: subagent:<uuid>: subagent:<uuid> | 孙子 Agent | 永远不行 |
1.4 子Agent结果回传机制
子Agent跑完后不会自动消失,它会执行一个announce步骤,把结果汇报给调用者。
Depth-2 叶子完成 → 汇报给 depth-1 父节点 depth-1 父节点收到 → 整合结果 → 汇报给主 Agent 主 Agent 收到 → 组织语言 → 发给用户
每个层级只看到直接子节点发回来的announce,消息末尾会带一行统计信息:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 🧹 Runs: 1 (0 succeeded, 1 failed) ⏱️ Duration: 2m 34s 📝 Tokens: 12.3K (in: 8.1K, out: 4.2K) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1.5 线程绑定
默认情况下,子Agent跑完就结束了,但如果开了 thread: true,子 Agent 会绑定到频道的某个线程上,后续在这个线程里的跟进消息会继续路由到这个子Agent会话。
{ tool: 'sessions_spawn', input: { task: "帮我重构这个 API", thread: true, mode: "session" } }
用户可以用 /focus <label> 手动切换当前线程绑定,用 /unfocus 解绑,用 /session ttl 查看或修改自动解绑时间。
二、工具系统的实现
2.1 工具组装过程
Agent每个Turn能看到哪些工具,不是一成不变的,这是一个层层过滤的过程:
原始工具列表 ↓ 来源合并(pi-coding-agent 的 codingTools + OpenClaw 原生工具) ↓ Schema 规范化(处理不同 provider 的兼容性quirks) ↓ 策略管道应用(全局 → Agent → 沙箱 → Provider) ↓ 前后置钩子包装(loop detection、before/after hook) ↓ 最终工具列表 → 发送给模型
工具来自两个地方:
-
pi-coding-agent 的 codingTools:
read、bash、edit、write这些基础工具 -
OpenClaw原生工具:在
src/agents/openclaw-tools.ts里定义的所有其他工具
2.2 Schema规范化
不同模型提供商对工具schema的要求不一样。OpenClaw在发送前会做一轮清理,比如:
-
某些provider要求参数顺序
-
某些provider不支持特定参数类型
-
某些provider对描述字段长度有限制
这个规范化在 pi-tool-definition-adapter.ts 里处理。最关键的适配是执行签名的转换:
// pi-agent-core 的 AgentTool 签名 execute(toolCallId: string, params: any, signal: AbortSignal, onUpdate?: () => void) // pi-coding-agent 的 ToolDefinition 签名 execute(toolCallId: string, params: any, onUpdate: () => void, ctx: any, signal: AbortSignal)
2.3 策略管道
工具最终能不能用,由多层策略决定,应用顺序如下:
-
全局策略:
tools.allow/tools.deny -
Agent 策略:
agents.list[].tools.allow/deny -
沙箱策略:沙箱模式下的额外限制
-
Provider 策略:
tools.byProvider对特定模型的额外限制
每一层都只能收紧工具集,不能放宽。
{ "tools": { "allow": ["read", "write", "exec"], // 全局允许这些 "deny": ["gateway"] // 全局禁止这些 }, "agents": { "list": [{ "id": "restricted", "tools": { "deny": ["exec"] // 这个 Agent 额外禁止 exec } }] }, "tools": { "byProvider": { "google-gemini-2-0-flash": { "deny": ["browser"] // Gemini 模型禁用浏览器工具 } } } }
最终这个「restricted」Agent用Gemini 2.0 Flash模型时,只剩下 read 和 write工具可用,exec 被全局禁了,而browser 被 provider策略禁了。
2.4 简化配置的工具组
在OpenClaw的设计中,写一长串工具名很麻烦,可以用组名进行简化。
| 组名 | 包含工具 |
|---|---|
group: runtime | exec, bash, process |
group: fs | read, write, edit, apply_patch |
group: sessions | sessions_list, sessions_history, sessions_send, sessions_spawn, session_status |
group: memory | memory_search, memory_get |
group: web | web_search, web_fetch |
group: ui | browser, canvas |
group: automation | cron, gateway |
group: messaging | message |
group: nodes | nodes |
group: openclaw | 所有内置 OpenClaw 工具 |
有了上述定义好的工具组,工具禁用同样可以使用简化的写法:
{ "tools": { "deny": ["group:runtime", "group:automation"] } }
2.5 工具结果返回
工具执行完后,结果以特定格式返回给模型。
// 成功结果 { role: "tool_result", tool_use_id: "toolu_xxx", content: [ { type: "text", text: "文件内容..." } ] } // 错误结果 { role: "tool_result", tool_use_id: "toolu_xxx", content: [ { type: "text", text: "Error: 文件不存在" } ] }
注意这里没有 isError 字段,所以模型需要从文本内容判断是否出错,这也是为什么模型有时候会忽略错误继续尝试。
长时间运行的会话,工具结果可能会持续膨胀。OpenClaw在持久化时会裁剪结果中的 schema字段,只保留实际数据。
// 持久化前 { result: "data", schema: { /* huge schema */ }, $schema: "http://..." } // 持久化后 { result: "data" }
这能显著减少session文件大小和token的消耗。
2.6 工具循环限制
如果模型连续多次调用同一个工具、读同一个文件、执行同一个命令,这通常是陷入了无效循环,OpenClaw 可以在检测到这种情况时自动干预。
{ "tools": { "loopDetection": { "enabled": true, "maxConsecutiveCalls": 3, "maxSameFileReads": 5 } } }
触发后会注入一个提示告诉模型「你已经对这个文件操作 N 次了」,让它换个思路处理,不要陷入死循环。
三、总结
之前也分析了很多Agent的框架,不难发现,多Agent协作从本质上来看就是个金字塔架构,顶层指挥,中间调度,底层干活,各层各管各的事。主Agent派个任务下去,子Agent在自己的一亩三分地里折腾,折腾完了举举手说「我好了」,主Agent再把结果拿走。但这套架构能运转起来,靠的是一堆看不见的细节,比如工具的权限怎么设计、工具是否可以嵌套使用、Agent消息如何回传等等,如果细节设计不合理,配出来的东西要么转不起来,要么转起来全是bug。
总之,多Agent这东西,设计好了是生产力,设计不好就是灾难。与其盲目抄配置,不如先把背后的门道搞清楚,再根据实际需求决定如何设计,省得一路踩坑。
推荐阅读

综上来看,OpenDataLoader的混合模式设计巧妙地平衡了处理速度与准确度,而支持边界框输出功能更是完美契合LLM和RAG场景。对于需要本地处理、保护数据隐私、或者有RAG场景需求的开发者,OpenDataLoader是值得考虑的选择之一。
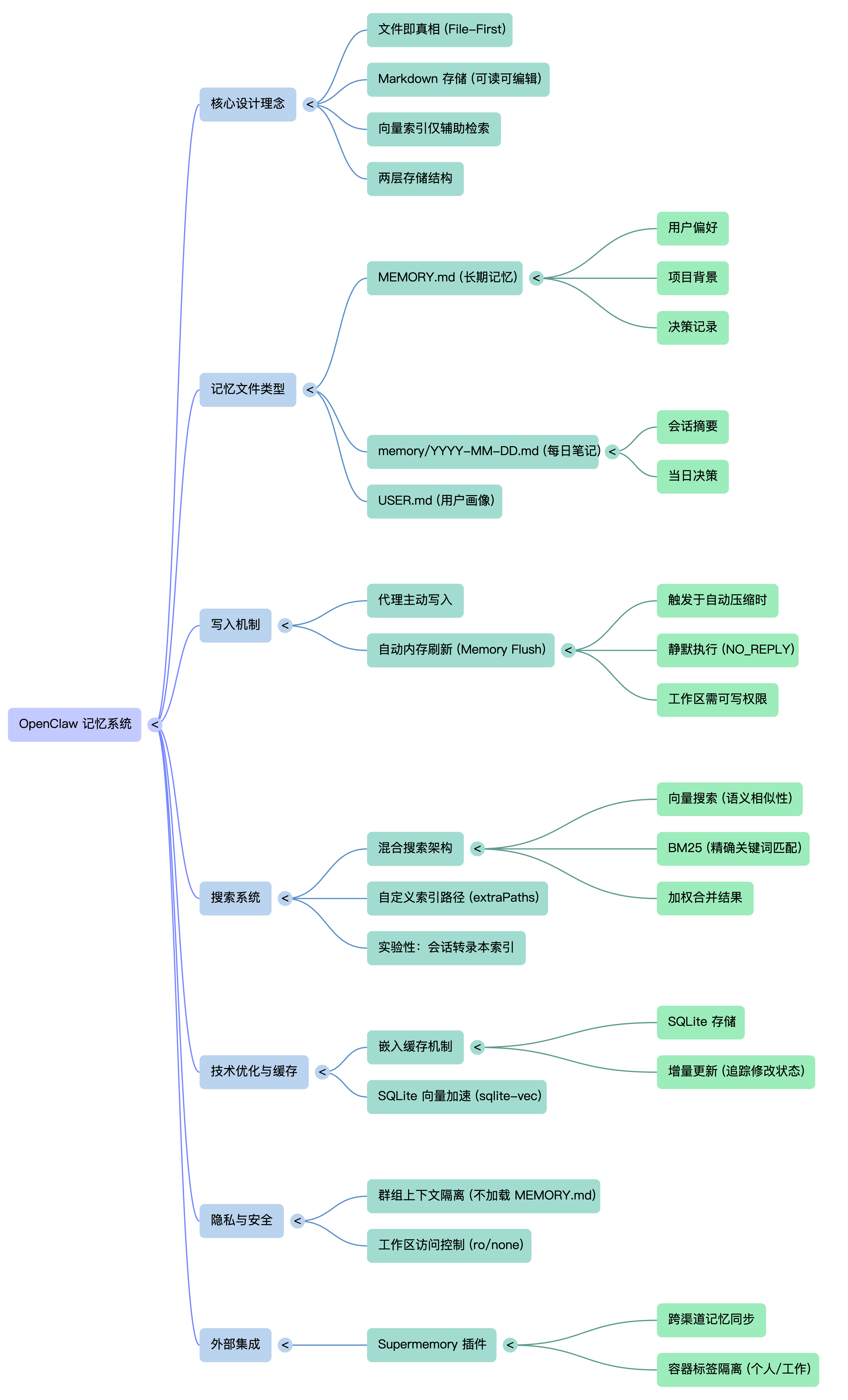
OpenClaw选了一条中间路线,与Skills类似,记忆是普通的Markdown文件,而且也是放在本地的磁盘上进行存储的。
