OpenClaw记忆系统深度解析
用过Agent的人都有一个共同的痛点,每次打开新会话,AI就把之前告诉它的事忘得干干净净。比如你说了一次「我最近在学OpenClaw」,下次它还是问你「有什么我可以帮你的」。传统方案有两个极端,要么把所有历史塞进上下文窗口,这样很快token就不够用了;要么全靠向量数据库存记忆,但这样做你根本不知道 AI 记住了什么,很多情况下想改都改不了。
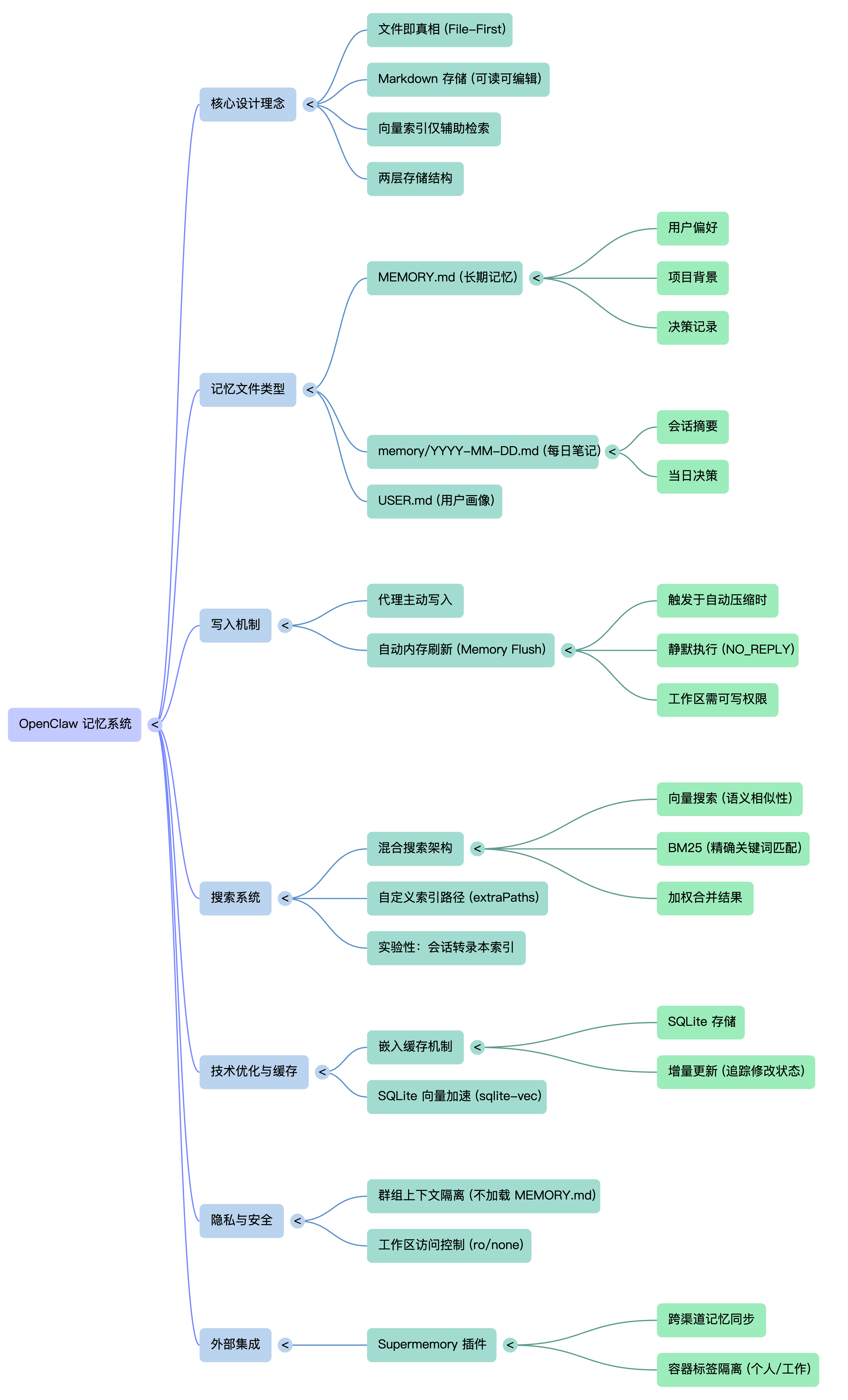
OpenClaw选了一条中间路线,与Skills类似,记忆是普通的Markdown文件,而且也是放在本地的磁盘上进行存储的。
一、万物即可文件化
说白了,OpenClaw 记忆系统的原则就是,Markdown文件是唯一的事实来源,模型只有在内容被写入磁盘后才会记住,这跟那些把向量数据库当唯一记忆的系统完全不一样。
这样做有什么好处呢?你可以用任何编辑器打开记忆文件查看内容,不用什么特殊工具。如果AI 写错了,直接进去改就行。不想让AI记住某件事,那么直接删掉那行字就完事了。
向量数据库在这里的角色纯粹是辅助。向量索引只是为了加快搜索速度,原始数据永远是Markdown文件。换句话说,就算索引全炸了,重建就行,记忆不会丢。
二、记忆的两层结构
OpenClaw的默认工作区用两层结构:日常笔记 + 长期记忆。
日常笔记就是 memory/YYYY-MM-DD.md,每天的对话摘要往里塞,记录“今天发生了什么”。格式比较随意,主要是给近期参考用。
长期记忆是 MEMORY.md,经过筛选和整理的重要信息,比如用户的偏好设置、项目背景、关键决策等这些需要跨会话保持的东西,会在适当的时候放进去。
还有个 USER.md,也是一种记忆文件,主要存放特定用户的个人信息。在对话时加载对应的用户画像,提供更个性化的回应。
~/.openclaw/agents/<agentid>/workspace/ ├── MEMORY.md # 长期记忆 ├── memory/ │ ├── 2026-03-15.md │ ├── 2026-03-16.md │ └── 2026-03-17.md ├── USER.md # 用户画像 └── ... </agentid>
三、记忆写入时机
两种方式。
第一种是由Agent主动写入。当代理判断某些信息值得长期记住,就调用记忆写入工具保存到Markdown文件里。通常发生在用户说「帮我记住这个」等这种有明确关键字眼的对话,或者Agent觉得某些上下文对后续对话很重要时。
第二种是自动内存刷新。当会话太长快触发自动压缩时,OpenClaw会偷偷跑一个静默轮次,提醒模型赶紧把重要信息写进持久化记忆,不然一会儿就被压缩没了。这是我个人觉得比较新颖的一点。
// 自动内存刷新伪代码 async function triggerMemoryFlush(session: Session): Promise<void> { // 检查是否快到压缩阈值 if (!isNearCompactionThreshold(session)) { return; } // 工作区能写吗 if (!session.workspace.isWritable) { return; } // 构建提示,让 AI 写记忆 const flushPrompt = buildMemoryFlushPrompt(session); // 静默执行,用户看不到这个轮次 const result = await runSilentAgentTurn(session, flushPrompt); // AI 说完了,检查是不是 NO_REPLY if (result.shouldNotReply) { await saveMemoryToDisk(result.durableNotes); } } </void>
刷新只在压缩周期中进行,而且工作区必须是可写的。沙箱模式下会跳过,因为在受限环境下不能随便写文件。
并且在默认情况下,用户完全感知不到这个静默轮次,记忆悄悄存了,但对话体验不受影响。
四、搜索系统
(一)向量搜索
可以对MEMORY.md和memory/*.md建立向量索引,语义查询能找到相关内容。比如搜「之前讨论的数据库优化方案」,能找到之前讨论的数据库的相关设计,尽管关键词没有完全匹配。这对长期记忆特别关键,因为人描述同一件事往往用不同的词。
// 记忆搜索工具调用 const searchResults = await callTool('memory_search', { query: '之前讨论的数据库优化方案', maxResults: 5 }); // 返回 // [ // { file: 'MEMORY.md', content: '...', score: 0.92 }, // { file: 'memory/2026-03-15.md', content: '...', score: 0.87 } // ]
(二)混合搜索
OpenClaw还搞了个混合搜索,结合BM25和向量搜索,并行跑两种检索,然后加权合并。BM25 擅长精确匹配,向量擅长语义相似性,各有各的用处。
// 混合搜索伪代码 async function hybridSearch(query: string, options: SearchOptions) { const [vectorResults, bm25Results] = await Promise.all([ vectorSearch(query, options), bm25Search(query, options) ]); // BM25 排名转分数 const bm25Scores = normalizeBm25Scores(bm25Results); // 按 chunk ID 合并 const merged = mergeByChunkId(vectorResults, bm25Scores); // 加权计算 const weightedResults = merged.map(item => ({ ...item, score: (item.vectorScore * 0.6) + (item.bm25Score * 0.4) })); return sortByScore(weightedResults).slice(0, options.maxResults); }
混合检索这种方式在RAG中已经不足为奇了,算是一种比较成熟的方案。
(三)配置
向量搜索需要选嵌入服务提供商。本地模式用预下载的模型,不用API密钥。远程模式支持OpenAI、Gemini 等厂商,其他的自定义OpenAI兼容端点(比如 OpenRouter、vLLM的)也行。
{ "memorySearch": { "provider": "openai", "model": "text-embedding-3-small", "remote": { "apiKey": "${OPENAI_API_KEY}" }, "fallback": "local" } }
五、嵌入缓存
每次更新记忆文件都要重新算嵌入的话,成本太高了。OpenClaw用SQLite缓存嵌入,只有变动的分块需要重新算。
// 嵌入缓存伪代码 class EmbeddingCache { private db: SQLite.Database; async getCachedEmbedding(chunkId: string): Promise<number[] |="" null=""> { const row = await this.db.query( 'SELECT embedding FROM chunk_embeddings WHERE chunk_id = ?', [chunkId] ); return row ? JSON.parse(row.embedding) : null; } async cacheEmbedding(chunkId: string, embedding: number[]): Promise<void> { await this.db.run( 'INSERT OR REPLACE INTO chunk_embeddings (chunk_id, embedding, updated_at) VALUES (?, ?, ?)', [chunkId, JSON.stringify(embedding), Date.now()] ); } } </void></number[]>
缓存默认开启,路径可配置。
六、SQLite 向量加速
如果sqlite-vec插件可用,嵌入向量直接存 SQLite 虚拟表,向量距离查询在数据库里跑。不需要把所有嵌入加载到内存,搜索也能保持快速响应。
{ "memorySearch": { "vectorStore": { "useSqliteVec": true, "tableName": "vec0" } } }
七、额外的记忆路径
除了默认的工作区,还能指定额外的Markdown文件路径加入索引:
{ "memorySearch": { "extraPaths": [ "/path/to/project/docs", "/path/to/notes/research.md" ] } }
额外路径的文件会加入向量索引,但不会自动加载到会话上下文里,这是因为额外路径主要用于检索目的。只有
MEMORY.md和memory/*.md会在新会话开始时加载。
八、两个记忆工具
OpenClaw暴露了两个工具给Agent用:memory_search 做语义检索,memory_append 追加内容到记忆文件。
禁用的话:
{ "plugins": { "slots": { "memory": "none" } } }
九、隐私与安全
(一)群组上下文隔离
MEMORY.md只在私密会话中加载,群组上下文绝对不加载。这意味着你在私信里告诉 AI 的敏感信息,不会因为群组成员问问题就被泄露。这在团队协作场景特别重要,你可能希望 AI 记住你个人的偏好,但不希望在群组对话里无意暴露。
(二)工作区访问控制
沙箱模式下工作区访问受限。workspaceAccess设为ro或none时,Agent无法写入记忆文件,自动刷新也会跳过。
十、总结
OpenClaw的记忆系统在人类能看懂和机器能检索之间找到了平衡点:
文件优先的策略保证了记忆的透明性,随时能看、能改、能删。两层记忆结构(每日笔记 + 长期记忆)给不同类型的信息提供了合适的归宿。自动内存刷新机制确保重要信息在上下文压缩时不会人间蒸发。向量搜索加混合搜索提供了强大的检索能力,让AI能快速找到相关内容。
OpenClaw之所以爆火,可能这种个性化的记忆系统也起到了一定作用吧。
推荐阅读

多Agent协作从本质上来看就是个金字塔架构,顶层指挥,中间调度,底层干活,各层各管各的事。
在OpenClaw的架构中,会话管理是连接 AI Agent与多渠道消息系统的核心枢纽。与传统的 CLI 工具不同,OpenClaw 运行的是一个持久化的守护进程,这个进程需要在一段时间内维护与多个用户、多个渠道的对话状态。
