PGML:向量数据库内一体化的RAG框架
RAGLLMVectorDB
架构总览
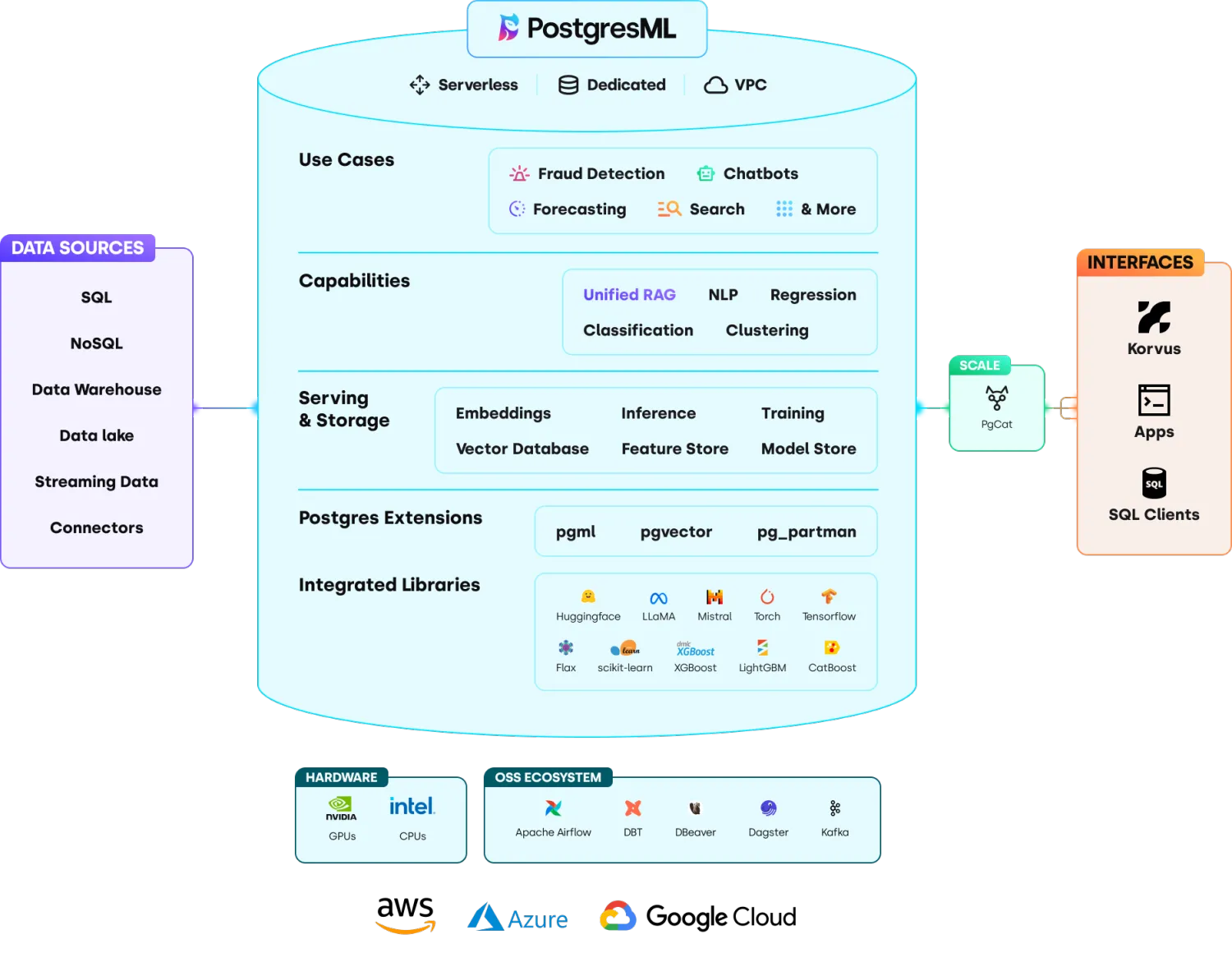
特性:
● 支持数据库中进行的ai和ml分析
● 支持gpu加速
● 集成多种开源llm和rag框架
● 支持传统的机器学习模型
使用方法
云端试用
官方提供了云服务试用,根据要求注册账号即可: 注册地址
本地部署
官方提供了docker镜像,执行如下命令即可安装
docker run \ -it \ -v postgresml_data:/var/lib/postgresql \ -p 5433:5432 \ -p 8000:8000 \ ghcr.io/postgresml/postgresml:2.7.12 \ sudo -u postgresml psql -d postgresml
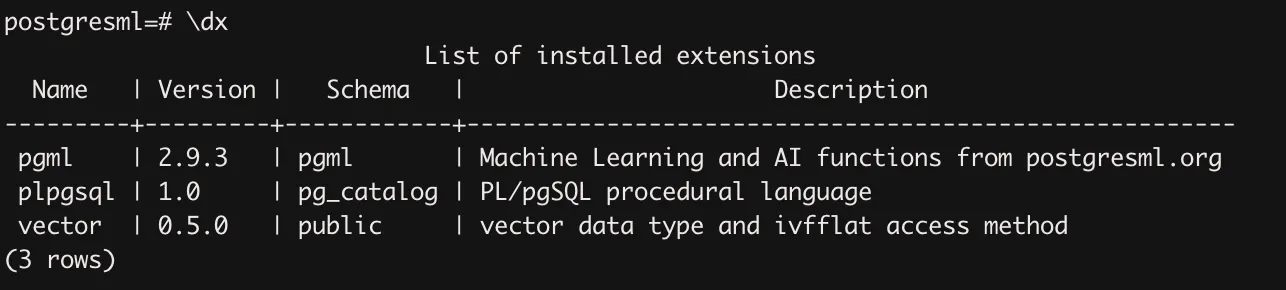
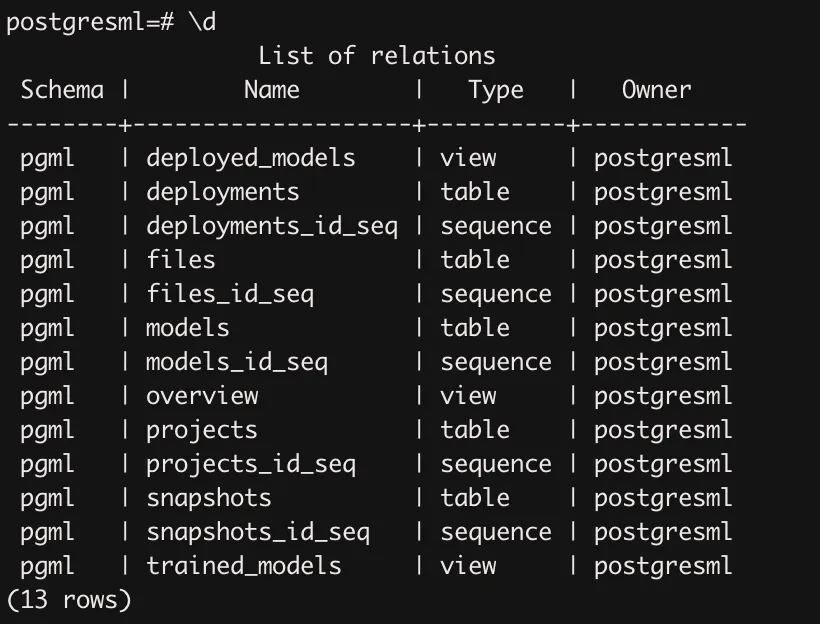
进入容器后,可选发现预先定义好一些表,同时已经安装了pgvector和pgml插件
一体化RAG框架
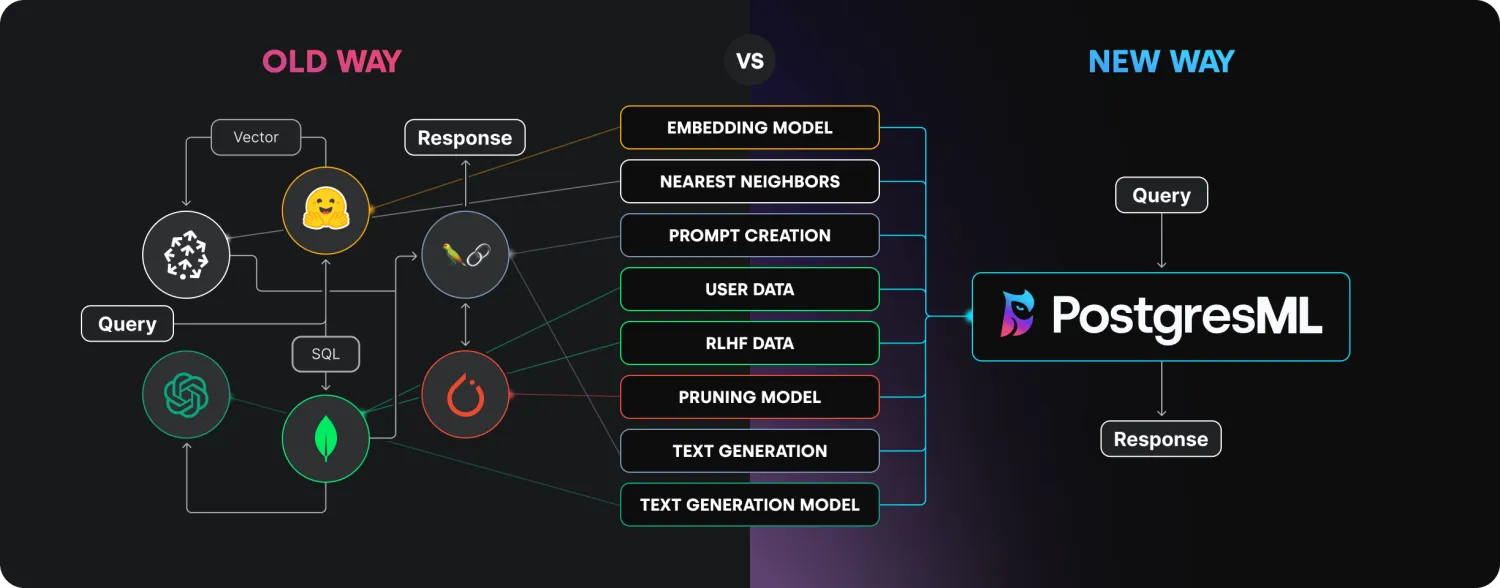
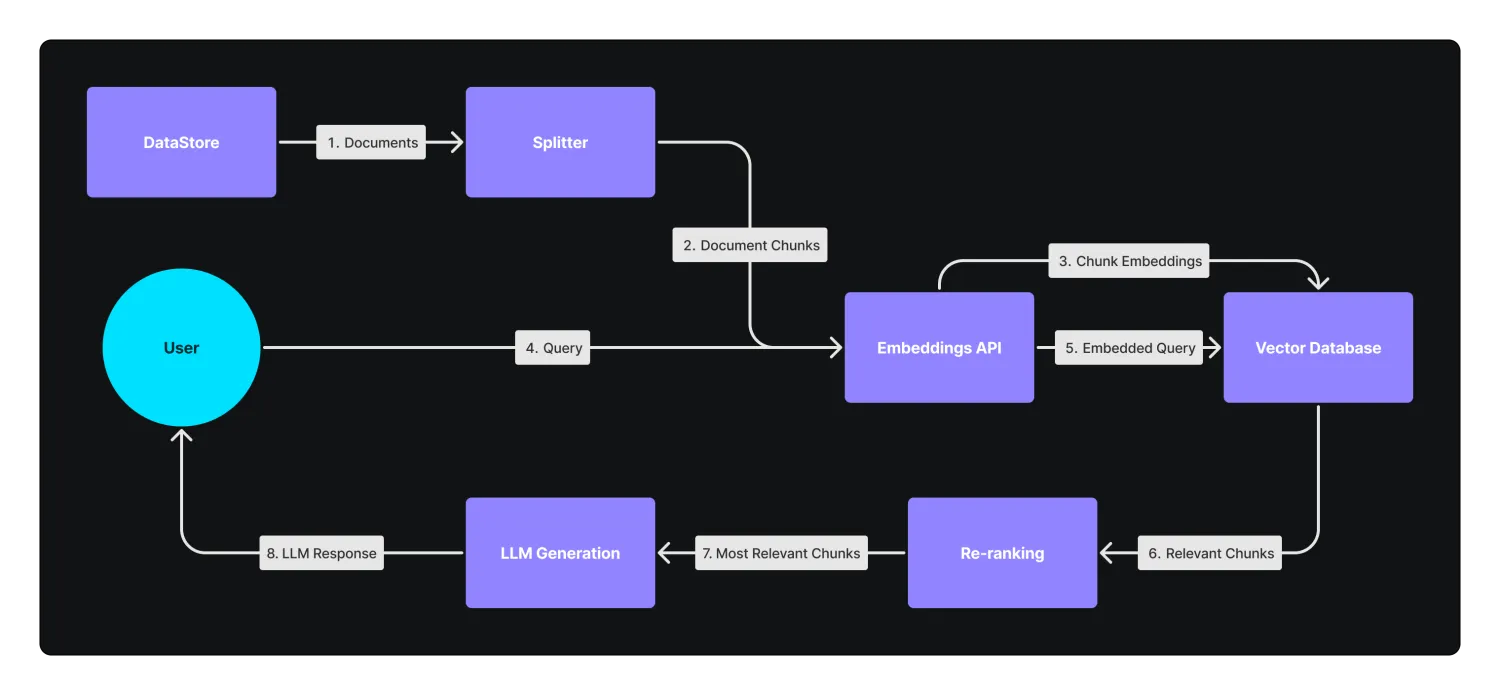
PGML的一体化RAG是针对传统RAG进行改进的解决方案。一体化的RAG不再依赖分散的模块来处理嵌入、检索、重排和文本生成,而是将它们组合在一项服务下。PGML提供了如下RAG基本步骤:
- 文档切分模块:用于把完整文档按照不同的切分策略进行切分
- 向量化模块:支持使用开源向量模型对文本块进行向量化表示
- 检索模块:用于对输入向量和文档向量进行相似性检索或者重排序
- 答案生成模块:支持使用开源的LLM对答案进行总结生成
文档切分
# 算子为pgml.chunk # pgml.chunk( # splitter TEXT, -- splitter name # text TEXT, -- text to embed # kwargs JSON -- optional arguments # ) # 实际例子如下 SELECT pgml.chunk('recursive_character', content, '{"chunk_size": 250}') FROM documents;
切分策略与langchain基本差不多,recursive_character是最常用的。此外还支持latex、markdown、ntlk、python、spacy等切分策略。
文档向量化
# 算子为pgml.embed # pgml.embed( # transformer TEXT, # "text" TEXT, # kwargs JSONB #) # 实际例子如下 SELECT pgml.embed('mixedbread-ai/mxbai-embed-large-v1', chunk) from chunks;
检索和重排序
# 算子为pgml.rank # pgml.rank( # transformer TEXT, # query TEXT, # documents TEXT[], # kwargs JSONB # ) # 实际例子如下 SELECT pgml.rank('mixedbread-ai/mxbai-rerank-base-v1', 'How do I write a select statement with pgml.transform?', array_agg("chunk"), '{"return_documents": false, "top_k": 6}'::jsonb || '{}') AS rank
文本生成
# 算子为pgml.transform # SELECT pgml.transform( # task => TEXT OR JSONB, -- Pipeline initializer arguments # inputs => TEXT[] OR BYTEA[], -- inputs for inference # args => JSONB -- (optional) arguments to the pipeline. # ) # 实际例子如下 SELECT * FROM pgml.transform( task => 'text-generation', inputs => ARRAY['In a galaxy far far away'] );
完整应用方案
第一步 创建一张表,用于存储文档切分的结果
CREATE TABLE chunks(id SERIAL PRIMARY KEY, chunk text NOT NULL, chunk_index int NOT NULL, document_id int references documents(id)); INSERT INTO chunks (chunk, chunk_index, document_id) SELECT (chunk).chunk, (chunk).chunk_index, id FROM ( SELECT pgml.chunk('recursive_character', document, '{"chunk_size": 250}') chunk, id FROM documents) sub_query;
第二步 创建向量表,把chunk进行embedding并存储
CREATE TABLE embeddings ( id SERIAL PRIMARY KEY, chunk_id bigint, embedding vector (1024), FOREIGN KEY (chunk_id) REFERENCES chunks (id) ON DELETE CASCADE ); INSERT INTO embeddings(chunk_id, embedding) SELECT id, pgml.embed('mixedbread-ai/mxbai-embed-large-v1', chunk) FROM chunks;
前两步可以在直接在一张表中创建两个字段保存即可,无需创建两个表
第三步 输入执行向量化,并按照对数据库中的向量进行检索排序
WITH embedded_query AS ( SELECT pgml.embed('mixedbread-ai/mxbai-embed-large-v1', 'How do I write a select statement with pgml.transform?', '{"prompt": "Represent this sentence for searching relevant passages: "}')::vector embedding ) SELECT chunks.id, ( SELECT embedding FROM embedded_query) <=> embeddings.embedding cosine_distance, chunks.chunk FROM chunks INNER JOIN embeddings ON embeddings.chunk_id = chunks.id ORDER BY embeddings.embedding <=> ( SELECT embedding FROM embedded_query) LIMIT 6;
第四步 对数据库中的相似片段进行总结生成
# 省略上述检索步骤 SELECT pgml.transform ( task => '{ "task": "conversational", "model": "meta-llama/Meta-Llama-3.1-8B-Instruct" }'::jsonb, inputs => ARRAY['{"role": "system", "content": "You are a friendly and helpful chatbot."}'::jsonb, jsonb_build_object('role', 'user', 'content', replace('Given the context answer the following question: How do I write a select statement with pgml.transform? Context:\n\n{CONTEXT}', '{CONTEXT}', chunk))], args => '{ "max_new_tokens": 100 }'::jsonb) FROM context;
transform改成transform_stream即变成流式输出
总结分析
优点:
● 一体化的RAG框架,集成了多种开源模型和langchain的组件,可以直接在数据库中进行RAG构建
● 支持多种机器学习算法,可以实现数据库内一站式的机器学习和数据分析
● 全程SQL操作即可,适合传统数据分析人员或者对框架和其他编程语言不熟悉的人
缺点:
● 镜像内不含模型,实时拉取模型会比较慢
● 不支持单独部署成一个服务,但是可以结合官方提供的Python和JS的SDK进行二次封装
● 由于数据库的安全问题不支持直接接入闭源模型,需要手工调整工作流程
推荐阅读

PostgreSQL 数据库向量化的核心:pgvector
pgvector是一款开源的向量搜索引擎,除了具备所有Postgres数据库的特性外,最主要的特点是能在Postgres数据库存储和检索向量数据,支持向量的精确检索和模糊检索
Chunkr:在线PDF文档解析与OCR工具
Chunkr,一个在线的PDF文档解析与OCR工具
