一文了解大模型性能评测数据、指标以及框架
笔者最近在对比浏览各种大模型性能时,发现不少机构发布的大模型成绩不是那么详细。排行榜仅存在数据集和分数,对于大多数人来说,可能就看个分数高低就忽略了。因此,本文整理了一些常见的评测数据集和指标说明,希望对于普通读者有所帮助。
常见评测数据集
| 名称 | 描述 | 类别 | 语言 | 评估指标 | 数量 | 发布机构 |
|---|---|---|---|---|---|---|
| MMLU | 一个涵盖 57 个主题的多项选择题基准,用于评估大规模语言模型的知识和推理能力。 | 知识问答 | 英语 | Accuracy | 15000 | University of California, Berkeley |
| MMLU Pro | MMLU 的专业级别版本,包含更具挑战性的问题,旨在评估模型在专业领域的理解和推理能力。 | 知识问答 | 英语 | Accuracy | 38500 | Berkeley Artificial Intelligence Research |
| GSM8K | 一个包含 8500 道小学数学题的基准,用于评估模型的数学推理能力。 | 数学推理 | 英语 | Accuracy | 8500 | |
| HumanEval | 一个包含 164 个手写编程问题的基准,用于评估模型生成代码的能力。 | 代码生成 | 英语 | Pass@k | 164 | OpenAI |
| MBPP | 一个包含 974 个简单的 Python 编程问题的基准,用于评估模型生成代码的能力。 | 代码生成 | 英语 | Pass@k | 974 | |
| HellaSwag | 一个包含 70,000 个多项选择题的基准,用于评估模型的常识推理能力。 | 常识推理 | 英语 | Accuracy | 70000 | University of Washington |
| ARC | 一个包含 7787 个多项选择题的基准,用于评估模型的常识推理能力。 | 常识推理 | 英语 | Accuracy | 7787 | Allen Institute for AI |
| TruthfulQA | 一个包含 817 个问题的基准,旨在评估模型是否能够生成真实且准确的答案,而不是编造信息。 | 真实性评估 | 英语 | Accuracy | 817 | |
| BIG-bench | 一个包含 200 多个不同任务的综合基准,用于评估模型的各种能力,包括推理、语言理解和知识。 | 综合评估 | 多语言 | Varies | 200 | |
| C-Eval | 一个涵盖人文社科、理工科等多个学科的中文多项选择题基准,用于评估模型在中文环境下的知识和推理能力。 | 知识问答 | 中文 | Accuracy | 13948 | 清华大学等 |
| SuperGLUE | 一个包含 8 个自然语言理解任务的基准,旨在评估模型在复杂的语言理解和推理任务上的性能。 | 自然语言理解 | 英语 | Varies | 8 | NYU & Facebook AI |
| DROP | 一个需要模型进行离散推理的阅读理解基准,包括计数、比较和排序等操作。 | 阅读理解 | 英语 | f1 | 96000 | Allen Institute for AI |
| MATH | 一个具有挑战性的数学问题数据集,包含代数、微积分、几何、概率等多个领域。 | 数学推理 | 英语 | Accuracy | 12500 | |
| BBH | BIG-Bench 的困难子集,包含更具挑战性的任务,用于评估模型的极限能力。 | 综合评估 | 英语 | Varies | 23 | |
| HLE | 研究生水平以上的超高难度、覆盖超多学科的大模型评测基准 | 知识问答 | 英语 | Accuracy | 3000 | Center for AI Safety |
| GPQA Diamond | 测试模型在多种推理场景下的能力,并推动大模型在更加复杂任务上的改进。 | 常识推理 | 英语 | Accuracy<br/> | 198 | CohereAI |
| SimpleQA | OpenAI发布的一个针对大模型事实问答的能力评测基准,可以有效检验模型幻觉严重程度 | 真实性评估 | 英语 | Accuracy | 4326 | OpenAI |
| SWE-bench | 一个从GitHub上提炼的真实世界的Python代码仓的任务评测数据集 | 代码生成 | 英语 | Accuracy | 2294 | 普林斯顿大学 |
| SWE-bench Verified | OpenAI基于SWE-Bench提炼的更加准确和更具代表性的大模型代码工程任务解决能力评测 | 代码生成 | 英语 | Accuracy | 500 | OpenAI |
| MATH-500 | OpenAI从MATH评测数据集中精选的500个更具代表性的数学评测基准 | 数学推理 | 英语 | Accuracy | 500 | OpenAI |
大模式日新月异,随着性能不断提升,老的数据集可能也会被逐步替换或淘汰,各种研究机构也会不断推出新的数据集。这里仅展示比较常见的一些数据集,用于研究学习使用,方便读者举一反三。
数据集示例及测试脚本
问答场景
以mmlu为例,该数据集是选择题,用于评估大规模语言模型的知识和推理能力,常用的字段为question,choices,answer
{ "question": "Which of the following is a key function of the Golgi apparatus?", "choices": ["A) ATP synthesis", "B) Protein modification and sorting", "C) DNA replication", "D) Lipid breakdown"], "answer": "B", "subject": "biology", "source": "https://example.com/bio_questions" }
基于该数据集的测试代码,构造出一个prompt让模型从上下文选择答案。
from transformers import AutoModelForCausalLM, AutoTokenizer import torch import json import numpy as np from tqdm import tqdm class ModelEvaluator: def __init__(self, model_name="mistralai/Mistral-7B-v0.1"): self.tokenizer = AutoTokenizer.from_pretrained(model_name) self.model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.float16, device_map="auto" ) def evaluate_mmlu(self, dataset_path): """评估 MMLU 数据集""" correct = 0 total = 0 with open(dataset_path, 'r') as f: questions = json.load(f) for question in tqdm(questions): prompt = f"问题: {question['question']}\n选项:\nA. {question['choices'][0]}\nB. {question['choices'][1]}\nC. {question['choices'][2]}\nD. {question['choices'][3]}\n答案:" inputs = self.tokenizer(prompt, return_tensors="pt").to(self.model.device) outputs = self.model.generate( **inputs, max_new_tokens=5, temperature=0.1 ) response = self.tokenizer.decode(outputs[0], skip_special_tokens=True) predicted_answer = response[-1] # 取最后一个字符作为答案(假设模型只返回选项) if predicted_answer == question['answer']: correct += 1 total += 1 return correct / total
推理场景
以HellaSwag为例,该数据集也是选择题,主要用于评估模型的常识推理能力。常用的字段为ctx,endings,label
{ "activity_label": "Removing ice from car", "ctx": "Then, the man writes over the snow covering the window of a car, and a woman wearing winter clothes smiles. then", "endings": [ ", the man adds wax to the windshield and cuts it.", ", a person boards a ski lift, while two men support the head of the person...", ", the man starts scraping ice off the car window with a scraper.", ", the woman opens the car door and gets inside." ], "label": 2, "source_id": "activitynet~v_-1IBHYS3L-Y" }
同样是构造出一个prompt让模型从上下文选择答案。
def evaluate_hellaswag(self, dataset_path): """评估 HellaSwag 数据集""" correct = 0 total = 0 with open(dataset_path, 'r') as f: scenarios = json.load(f) for scenario in tqdm(scenarios): # 构建更完整的提示词 prompt = f"""基于给定的上下文,选择最合理的后续发展。 活动: {scenario['activity_label']} 上下文: {scenario['ctx']} 请选择最合理的后续发展: A. {scenario['endings'][0]} B. {scenario['endings'][1]} C. {scenario['endings'][2]} D. {scenario['endings'][3]} 请直接回答选项字母(A/B/C/D):""" inputs = self.tokenizer(prompt, return_tensors="pt").to(self.model.device) outputs = self.model.generate( **inputs, max_new_tokens=5, temperature=0.1 ) response = self.tokenizer.decode(outputs[0], skip_special_tokens=True) # 提取预测的选项 predicted_choice = self.extract_answer(response) # 将字母选项转换为数字索引 if predicted_choice: predicted_index = ord(predicted_choice) - ord('A') if predicted_index == scenario['label']: correct += 1 total += 1 return correct / total def extract_answer(self, response: str) -> str: import re match = re.search(r'[ABCD]', response) if match: return match.group(0) return None
数学场景
以MATH-500为例,该数据集属于简答题,主要用于评估模型的数学能力。常用的字段为problem,solution
\problem{Let $f(x)$ be a differentiable function satisfying $f(x+y) = f(x)f(y)$ for all $x,y \in \mathbb{R}$. Prove that $f(x) = e^{kx}$ for some constant $k$.} \solution{ 1. Let $x=0$, then $f(0+y) = f(0)f(y) \Rightarrow f(y) = f(0)f(y)$. Thus $f(0) = 1$. 2. Differentiate both sides w.r.t $x$: $f'(x+y) = f'(x)f(y)$. 3. Set $x=0$: $f'(y) = f'(0)f(y)$. This implies $f(y) = Ce^{f'(0)y}$. 4. Combine with $f(0)=1$: $C=1$, hence $f(x)=e^{kx}$ where $k=f'(0)$. }
数学题的评估比较复杂, 不再是判断结果是否正确,一般还需要对步骤进行评分,不同的评测框架可能有所不同,这里仅给出简单的评测思路。
def evaluate_math_problems(self, dataset_path): """评估数学问题解答""" correct = 0 total = 0 results = [] with open(dataset_path, 'r') as f: problems = json.load(f) for problem in tqdm(problems): # 构建提示词 prompt = f"""请解答以下数学问题,给出完整的解题步骤。 问题: {problem['problem']} 请按照以下格式给出解答: 1. [第一步推导] 2. [第二步推导] ... 最终结论: [结论] 你的解答:""" # 生成答案 inputs = self.tokenizer(prompt, return_tensors="pt").to(self.model.device) outputs = self.model.generate( **inputs, max_new_tokens=512, temperature=0.2, num_return_sequences=1 ) response = self.tokenizer.decode(outputs[0], skip_special_tokens=True) # 评估答案 score = self.evaluate_solution(response, problem['solution']) if score >= 0.8: # 设置阈值 correct += 1 total += 1 # 记录详细结果 results.append({ 'problem': problem['problem'], 'model_solution': response, 'reference_solution': problem['solution'], 'score': score }) return { 'accuracy': correct / total, 'detailed_results': results } def evaluate_solution(self, model_solution: str, reference_solution: str) -> float: """评估解答质量""" # 1. 提取关键步骤 model_steps = self.extract_solution_steps(model_solution) ref_steps = self.extract_solution_steps(reference_solution) # 2. 评分标准 score = 0.0 key_points = [ ('f(0) = 1', 0.25), # 第一步得出 f(0)=1 ('f\'(x+y)', 0.25), # 求导 ('f\'(y) = f\'(0)f(y)', 0.25), # 代入 x=0 ('e^{kx}', 0.25) # 最终结论 ] # 3. 检查每个关键点 for point, weight in key_points: if any(point.lower() in step.lower() for step in model_steps): score += weight return score def extract_solution_steps(self, solution: str) -> List[str]: """提取解答步骤""" # 移除 LaTeX 标记 solution = solution.replace('\\solution{', '').replace('}', '') # 分割步骤 steps = [] for line in solution.split('\n'): line = line.strip() if line and line[0].isdigit() and '.' in line: steps.append(line.split('.', 1)[1].strip()) return steps
代码场景
以SWE-bench为例,该数据集是GitHub上真实存在的issue,用于衡量模型解决真实软件问题的能力。
{ "repo": "pytorch/pytorch", "issue_id": 12345, "problem_statement": "Fix dimension mismatch in torch.nn.LSTM when batch_first=True", "code_context": "class LSTM(nn.Module):\n def forward(self, x):\n # Original code...", "patch": "diff --git a/torch/nn/modules/rnn.py b/torch/nn/modules/rnn.py\n+ if batch_first:\n+ x = x.transpose(0, 1)", "test_cases": ["test_lstm_batch_first_dim()"] }
代码生成问题一般用Pass@k指标进行衡量,用于评估模型生成代码的正确性和稳定性。
def evaluate_problem(self, problem: SWEBenchProblem) -> Dict: """评估单个问题的多次生成结果""" results = { "pass@1": 0, "pass@3": 0, "pass@5": 0, "generations": [] } # 构建提示词 prompt = self.create_prompt(problem) # 生成多次代码 for i in range(self.n_generations): # 生成代码 generated_code = self.generate_code(prompt) # 测试生成的代码 test_result = self.test_code(generated_code, problem) # 记录结果 results["generations"].append({ "code": generated_code, "passed": test_result["passed"], "error": test_result.get("error", None) }) # 更新 pass@k 指标 if test_result["passed"]: if i < 1: results["pass@1"] = 1 if i < 3: results["pass@3"] = 1 if i < 5: results["pass@5"] = 1 return results def create_prompt(self, problem: SWEBenchProblem) -> str: """创建代码生成提示词""" return f"""请修复以下 PyTorch 代码中的问题。 问题描述: {problem.problem_statement} 代码上下文: {problem.code_context} 需要通过的测试用例: {', '.join(problem.test_cases)} 参考修复 patch: {problem.patch} 请提供完整的修复后的代码:""" def generate_code(self, prompt: str) -> str: """生成代码""" inputs = self.tokenizer(prompt, return_tensors="pt").to(self.model.device) outputs = self.model.generate( **inputs, max_new_tokens=512, temperature=0.2, num_return_sequences=1 ) return self.tokenizer.decode(outputs[0], skip_special_tokens=True) def test_code(self, code: str, problem: SWEBenchProblem) -> Dict: """测试生成的代码""" result = { "passed": False, "error": None } try: # 创建临时文件 with tempfile.NamedTemporaryFile(suffix='.py', delete=False) as f: # 写入必要的导入 f.write(b"import torch\nimport torch.nn as nn\n\n") # 写入生成的代码 f.write(code.encode()) # 写入测试用例 for test in problem.test_cases: f.write(f"\n\n{test}".encode()) # 运行测试 process = subprocess.run( ['python', f.name], capture_output=True, text=True, timeout=30 # 30秒超时 ) # 检查测试结果 result["passed"] = process.returncode == 0 if not result["passed"]: result["error"] = process.stderr except Exception as e: result["error"] = str(e) finally: # 清理临时文件 if 'f' in locals(): os.unlink(f.name) return result
常见指标说明
1. Pass@k
● 定义:
在代码生成任务中,模型生成 k 个候选代码样本,其中至少有一个样本能通过单测的概率。
● 计算公式:
$Pass@k=\dfrac{至少一个正确的样本数}{总问题数} \times 100%$
● 应用场景:
HumanEval、SWE-bench 等代码生成任务,衡量模型生成正确代码的能力。
2. Accuracy(准确率)
● 定义:
这个是机器学习领域一个常见的指标,即分类任务中,正确预测的样本数占总样本数的比例。
● 计算公式:
$Accuracy=\dfrac{TP+TN}{TP+TN+FP+FN} \times 100%$
● 应用场景: MMLU、C-Eval 等多选题评测,要求模型在给定的上下文选项中选择正确答案。
3. F1 Score
● 定义:
精确率(Precision)和召回率(Recall)的调和平均数,同样也是机器学习的一个常用指标。
● 计算公式:
$Accuracy=2\times \dfrac{Precision \times Recall}{Precision+Recall}$
● 应用场景:
DROP等阅读理解任务中,要求模型进行理解并生成答案。
4.其他变体指标
4.1 Prompt Strict:
● 定义:
严格检查模型的输出是否满足提示词的所有要求(格式、内容、长度等),主要衡量模型的结构化输出能力。
● 应用场景:
需要严格的输出格式, 如结构化数据生成、API 接口调用等。
4.2 n-shot F1
● 定义:
使用了n-shot样本学习场景下的F1分数,相比F1提升了少样本,用于衡量模型的泛化能力。
● 应用场景:
文本生成任务,信息抽取,问答系统等传统nlp任务。
4.3 Pass@k-COT
● 定义:
评估k次生成中是否有正确的思维链推理过程
● 应用场景:
数学推理问题, 逻辑推理题等需要多步骤迭代计算等场景。
评测框架与工具
通过前面的分析对比可知,不同的数据集和指标的评测要求是不一样的,而生成模型的生成结果具有不确定性,例如一些不好的prompt可能会导致测评结果不可信,因此业界一般会按照统一的评测框架来进行对比,以此保证测试结果的公平性。
1. OpenCompass
OpenCompass是上海人工智能实验室一个开源的大模型评测框架,包含100+个常见的大模型评测数据集,同时支持主流开源模型和API,允许多个模型并行测试。使用方式非常简单,通过pip即可安装。并且针对国产昇腾芯片和框架进行了优化。
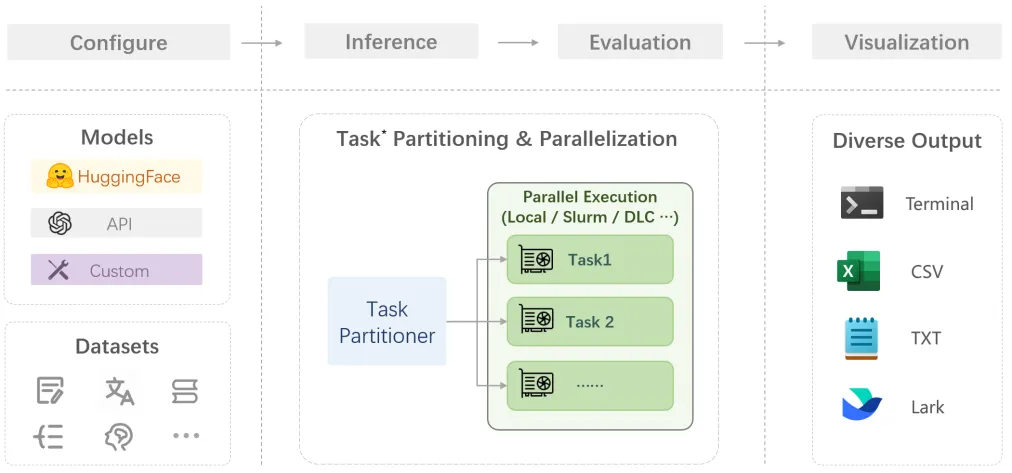
在 OpenCompass 中,每个评估任务由待测模型和数据集组成。评估的入口脚本是 run.py。可以通过命令行或配置文件修改要测试的模型或数据集。
启动测试脚本:
python run.py \ --datasets demo_gsm8k_chat_gen demo_math_chat_gen \ --hf-type chat \ --hf-path internlm/internlm2-chat-1_8b \ --debug
更多使用方法可参考官方教程: https://opencompass.readthedocs.io/zh-cn/latest/get_started/quick_start.html
2. LM Evaluation Harness
lm-evaluation-harness同样是一个开源的大模型评估框架,用户可通过YAML或Python脚本自定义评测任务,对于国外的大模型支持比较全面。
测试命令:
lm_eval --model hf \ --model_args pretrained=EleutherAI/gpt-j-6B \ --tasks hellaswag \ --device cuda:0 \ --batch_size 8
更多使用方法可参考官方教程: https://github.com/EleutherAI/lm-evaluation-harness
推荐阅读

DeepSeek的研究报告表明可以通过蒸馏技术让模型产生一定程度的推理能力,该方法兼顾经济效益和性能。

本文从DeepSeek官方推荐的应用或插件列表中,整理收集了一些比较热门或实用性较强的软件。
